降维
现代数据往往具有很高的维度。一张 的灰度图像就是 维向量;一篇文档的词袋表示可能有数千个词汇特征;基因表达数据甚至可能包含数万个基因维度。这种数据膨胀现象带来了两个棘手的问题:一是计算成本飙升。特征越多,模型训练越慢,内存占用越大。以线性回归为例,计算复杂度与特征维度的立方成正比,特征从 维增加到 维,计算量却翻了 倍;二是更为隐蔽却致命的问题,维度诅咒(Curse of Dimensionality)这个术语由美国数学家理查德·贝尔曼(Richard Bellman)在 1961 年提出,描述了高维空间中一系列反直觉的现象。想象一个单位立方体,在三维空间中,其体积为 ;但若将维度扩展到 维,单位超立方体的体积仍然是 ,而其对角线长度却达到了 。这意味着高维空间中,绝大部分点都集中在立方体的角落附近,中心区域几乎空无一物。更糟糕的是,距离度量在高维空间中逐渐失效,任意两点之间的距离趋于相等,"近邻"和"远邻"的区分变得模糊。
下图直观对比了二维单位正方形与三维单位立方体的几何差异。虽然两者的"体积"都是 ,但空间对角线长度从二维的 增加到三维的 。随着维度继续增长,对角线长度将远超边长,导致数据点越来越集中在超立方体的角落区域,中心区域的数据越来越少,这就是维度诅咒的几何本质。
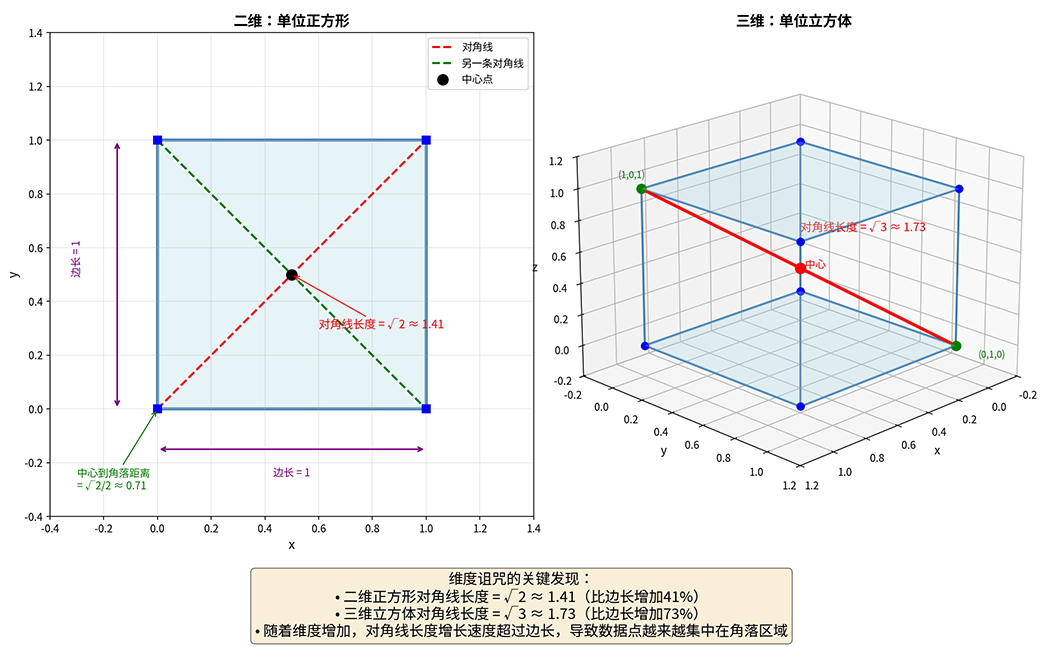
图:维度诅咒的直观理解:从二维到三维的几何变化
降维正是应对这两个问题的手段,它的基本思想是将高维数据投影到低维空间,同时尽可能保留原始数据的主要信息(由方差度量),去除噪声和冗余。降维有两个典型应用场景:
- 数据可视化:将高维数据降到 2 维或 3 维,绘制散点图,人类可以直观观察数据的聚类结构、异常点分布。
- 特征压缩:在分类或回归任务前,先用主成分分析(Principal Component Analysis,PCA)将特征数量从数千维压缩到数十维,显著提高后续模型的训练效率。
本章将深入讲解 PCA 的基本原理,从几何直觉出发,推导目标函数与求解方法,并通过代码实践验证其有效性。最后,我们将对比另一种降维方法:线性判别分析(LDA),理解无监督降维与有监督降维的本质区别。
PCA 数学原理
在深入数学推导之前,先以一个直观的例子理解 PCA 的思想。假设我们收集了某城市 100 套房屋的面积和总价数据,将这 100 个点绘制在二维坐标系中。数据呈现明显的正相关趋势:面积越大,价格越高。但仔细观察会发现,这些点并非完美排列成一条直线,而是在直线上下散开了一定的宽度,有的房屋单价偏高,有的偏低。请你思考一个问题:如果让你用一个维度来描述这 100 套房屋的特征(如用于后续的聚类或分类),应该选择哪个维度?
- 方案一是选择其中一个维度,譬如面积,丢弃价格维度。但这相当于只看横轴投影,信息损失严重,那些面积相同但价格差异悬殊的房屋被强行归为一类。
- 方案二是寻找一条最佳投影线,将二维平面上的每个点投影到这条直线上,得到一个一维坐标。什么样的投影线是最佳的?直觉告诉我们,投影后的点应该尽可能被区分开,而不是挤在一起。换句话说,投影后的数据方差应该最大化,这就是 PCA 的设计目标。
接下来将几何直觉转化为数学表达,并给出推导证明。给定 个样本 ,每个样本 是一个 维向量 ,PCA 的目标是找到一个投影方向 (满足单位长度约束 ),使得样本向量投影到这个方向后的方差最大化。因为方差衡量数据的分散程度,方差越大意味着投影后的数据点散布得越开,保留的信息越多。
朝着这个目标去设计 PCA 的目标函数。首先定义数据的均值和投影后的均值,原始数据的均值向量为 ,投影后的坐标为 (一个标量,可以理解为沿着方向 看到的位置),投影后的均值为 (投影后的"中心点")。投影后的方差定义为:
这个方差公式可以进一步简化。利用向量运算的性质,将方差表达式展开:
这里用到一个数学技巧,由于 是一个标量,等于其转置 ,因此可以拆成两部分相乘的形式,将 提到求和符号外面:
其中 是数据的协方差矩阵(Covariance Matrix)。里面的 是一个 的矩阵(中心化后的样本向量与自身的外积),表示单个样本偏离均值的方向和幅度。对所有样本求和并除以 ,就得到整体偏离情况的平均。协方差矩阵的对角线元素 是第 个特征的方差,非对角线元素 是第 和第 个特征的协方差(衡量两者的相关性)。至此,PCA 的目标函数已然清晰,就是要找到一个单位向量 ,使得 最大。这个优化问题的解揭示了 PCA 与协方差矩阵之间的联系:最优投影方向正是协方差矩阵的特征向量。
在无约束优化中,直接求导并令导数为零即可找到极值点。但当存在约束条件时,极值点往往不在自由极值的位置,而是在约束边界上,正则化原理部分曾经深入讨论过类似的场景。拉格朗日乘数法(Lagrange Multiplier Method)是处理这类约束优化问题的经典工具,具体到 PCA 的优化问题,约束条件 定义了一个单位球面,目标函数 在这个球面上的极值点,就是我们要找的最优投影方向。
拉格朗日乘数法的处理思路在支持向量机的拉格朗日对偶变换中已经应用过:构造拉格朗日函数,将约束条件融入目标函数,得到 ,这里 是原来的目标函数(投影后的方差), 则是约束条件的惩罚项。其中 是拉格朗日乘子(一个待定的参数),当 时,惩罚项为零;当 时,惩罚项不为零,迫使优化过程回到约束边界。
对 求偏导并令导数为零,得到方程 ,整理后得 。这正是特征值方程,从另外一个角度印证了最优投影方向 是协方差矩阵 的特征向量。将 与约束条件 代入目标函数,计算投影后的方差:
至此,结论已非常清晰:投影方差等于特征值 (同时也是拉格朗日乘子),这意味着协方差矩阵的特征值排序后,最大特征值对应的特征向量就是方差最大的投影方向(第一主成分),第二大特征值对应的特征向量是第二主成分,以此类推。特征值的大小直接量化了每个主成分保留的信息量。
PCA 投影与重构
PCA 提供了一个信息双向变换的工具,一方面可以将高维数据压缩到低维空间(投影),另一方面可以从低维表示恢复原始数据(重构),有点像文件压缩,但是是有损的。理解这个双向变换,有助于更深刻地认识 PCA 的信息处理机制。
从高维到低维投影:给定中心化后的数据矩阵 (,每行一个样本),投影到前 个主成分空间 , 是主成分矩阵(),每一列是一个主成分(特征向量)。结果 是投影后的数据(),每个样本从 维压缩到 维。 的每一列定义了一个投影方向, 相当于将每个样本分别投影到这 个方向上,得到 个投影坐标,这些投影坐标就是新的低维特征。
从低维到高维重构:降维的本质是信息压缩,不可避免地造成信息损失。PCA 的重构过程试图从低维表示恢复原始数据,但由于丢弃了后 个主成分,重构结果与原始数据之间势必存在一定误差。重构高维数据的公式为 ,其中 是低维表示(), 是主成分矩阵的转置(),两者相乘相当于将低维数据展开回高维空间(),但只恢复了前 个主成分的信息。最后, 是原始数据的均值,加回去是因为 PCA 在中心化时减去了均值。降维造成的信息损失可以使用重构误差(Reconstruction Error)来衡量,它定义为原始数据与重构数据之间的均方误差:
从公式定义可以看出,重构误差等于被丢弃主成分的特征值之和,这也完全符合直觉,因为特征值代表信息量(方差),丢弃的特征值越大,信息损失越严重。另一个常用的评估指标是方差解释比例(Explained Variance Ratio),表示前 个主成分保留的信息占总信息的比例:
假设一个三维数据集的协方差矩阵特征值为 ,,。总方差为 。若选择前 1 个主成分:方差解释比例 = ,若选择前 2 个主成分:方差解释比例 = 。这说明第一个主成分承载了绝大部分信息(80%),第二个主成分贡献了额外 16%,第三个主成分几乎无关紧要(仅 4%)。在这种情况下,将三维数据降到二维是十分合理的决策。
线性判别分析
到目前为止,我们讨论的都是无监督降维方法,只关注数据的整体方差结构,不考虑样本的类别标签。但在分类任务中,降维的目标可能不是保留最多信息,而是让不同类别的数据尽可能分开。这正是线性判别分析(Linear Discriminant Analysis,LDA)的设计初衷。
用一个例子理解 PCA 和 LDA 的区别:假设有两类数据,一类是健康人群的体检指标,另一类是患病人群的体检指标。每个样本有 10 个特征(血压、血糖、胆固醇等)。目标是降到 1 维,以便用一个阈值简单区分成两类。如果用 PCA 降维,它会找到方差最大的投影方向。但问题在于方差最大的方向未必是区分"健康"与"患病"的最佳方向,也许两类数据在这个方向上高度重叠。如果用 LDA 降维,它会找到让"健康类"和"患病类"投影后类间距离最大化、类内离散最小化的方向,即使这个方向的整体方差相对 PCA 较小,但它对分类最有价值。
LDA 的目标是找到一个投影方向 ,使得投影后类间距离最大化、类内离散最小化。假设有 个类别,第 类有 个样本,均值向量为 。全局均值向量为 。LDA 的目标函数就是:
- 是类间散度矩阵(Between-class Scatter Matrix),定义为 ,每个类别中心偏离全局中心的程度乘以该类别的样本数量,再加权求和,衡量不同类别中心之间的距离。 是投影后类间距离的度量(越大越好)。
- 是类内散度矩阵(Within-class Scatter Matrix),定义为 ,每个类别内部所有样本偏离该类别中心的程度求和汇总,衡量同一类别内部数据的离散程度。 是投影后类内离散的度量(越小越好)。
整个公式的结果是类间距离与类内离散的比值,最大化这个比值意味着类别之间尽可能分开,类别内部尽可能紧凑。显而易见,PCA 和 LDA 两种方法的区别与使用场景都在于是否利用类别标签信息:
| 特性 | PCA | LDA |
|---|---|---|
| 学习范式 | 无监督 | 有监督 |
| 目标函数 | 最大化投影方差 | 最大化类间/类内距离比 |
| 适用场景 | 无标签数据、可视化、特征压缩 | 有标签数据、分类预处理 |
| 线性假设 | 无特殊假设 | 假设各类服从正态分布且协方差相同 |
| 最大维度 | 可降到任意 维 | 最大降到 维(类别数减一) |
PCA 算法实践
理论推导完成后,用代码实践验证理解。下面的代码实现了完整的 PCA 算法流程:从中心化、协方差矩阵计算、特征分解,到投影和重构。使用经典的鸢尾花数据集进行测试,将 4 维特征降到 2 维,并验证重构误差与方差解释比例。
鸢尾花数据集包含 150 个样本,每个样本有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),分为 3 个类别(Setosa、Versicolor、Virginica)。这个数据集非常适合演示 PCA,4 维数据难以直接可视化(可视化将在应用场景的代码中演示),降到 2 维后可以清晰地观察类别分布。
import numpy as np
class PCA:
"""
主成分分析(Principal Component Analysis)实现
核心步骤(对应理论推导):
1. 数据中心化(减去均值)
2. 计算协方差矩阵 S = X^T X / (n-1)
3. 特征分解 S = V Λ V^T
4. 选择前 k 个特征值对应的特征向量作为主成分
5. 投影到主成分空间
参数说明:
n_components : int, 可选
要保留的主成分数量。若为 None,保留所有成分
"""
def __init__(self, n_components=None):
self.n_components = n_components
# 存储 PCA 结果
self.components_ = None # 主成分(特征向量矩阵)
self.explained_variance_ = None # 特征值(各主成分的方差)
self.explained_variance_ratio_ = None # 方差解释比例
self.mean_ = None # 数据均值向量
def fit(self, X):
"""
训练 PCA 模型
参数说明:
X : ndarray, shape (n_samples, n_features)
输入数据矩阵
返回:
self : PCA 对象实例
"""
n_samples, n_features = X.shape
# 步骤1:数据中心化(对应理论中的 x_i - x̄)
self.mean_ = X.mean(axis=0)
X_centered = X - self.mean_
# 步骤2:计算协方差矩阵(对应理论中的 S = 1/n Σ(x_i - x̄)(x_i - x̄)^T)
# 使用 n-1 而非 n,得到无偏估计(与 sklearn 一致)
cov_matrix = X_centered.T @ X_centered / (n_samples - 1)
# 步骤3:特征分解(对应理论中的 S = VΛV^T)
# np.linalg.eigh 专门用于对称矩阵,返回实数特征值
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 特征值和特征向量按降序排列(PCA 选择方差最大的方向)
indices = np.argsort(eigenvalues)[::-1]
eigenvalues = eigenvalues[indices]
eigenvectors = eigenvectors[:, indices]
# 存储特征值(对应理论中的 λ_j)
self.explained_variance_ = eigenvalues
# 步骤4:计算方差解释比例(对应理论中的 Σλ_j / Σλ_total)
total_variance = eigenvalues.sum()
self.explained_variance_ratio_ = eigenvalues / total_variance
# 确定主成分数量
if self.n_components is None:
self.n_components = n_features
# 步骤5:选择前 k 个主成分(对应理论中的 V_k)
self.components_ = eigenvectors[:, :self.n_components].T
return self
def transform(self, X):
"""
将数据投影到主成分空间
参数说明:
X : ndarray, shape (n_samples, n_features)
输入数据
返回:
Z : ndarray, shape (n_samples, n_components)
投影后的低维数据
"""
# 中心化后投影(对应理论中的 Z = X̃ V_k)
X_centered = X - self.mean_
return X_centered @ self.components_.T
def fit_transform(self, X):
"""训练并转换(一步完成)"""
self.fit(X)
return self.transform(X)
def inverse_transform(self, Z):
"""
从低维空间重构原始数据
参数说明:
Z : ndarray, shape (n_samples, n_components)
低维表示
返回:
X_reconstructed : ndarray, shape (n_samples, n_features)
重构的高维数据(加回均值)
"""
# 重构公式(对应理论中的 X̂ = Z V_k^T + x̄)
return Z @ self.components_ + self.mean_
# 测试:鸢尾花数据降维
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data # 150个样本,4维特征
y = iris.target # 3个类别标签
# PCA降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("=== PCA降维结果 ===")
print(f"原始维度: {X.shape[1]}")
print(f"降维后维度: {X_pca.shape[1]}")
print(f"\n各主成分解释比例: {pca.explained_variance_ratio_}")
print(f"累计解释比例: {pca.explained_variance_ratio_.sum():.3f}")
# 验证重构误差
X_reconstructed = pca.inverse_transform(X_pca)
reconstruction_error = np.mean((X - X_reconstructed) ** 2)
print(f"\n平均重构误差: {reconstruction_error:.6f}")
运行结果显示,鸢尾花数据的前两个主成分累积解释了约 的方差。这意味着仅用 2 维就能保留原始 4 维数据绝大部分的信息。第一个主成分贡献了约 92.4% 的方差,说明数据的"主要变化方向"集中在第一个维度,这与鸢尾花数据的特点一致:花瓣尺寸是区分品种的最主要特征。
重构误差约为 0.004,数值很小,说明从 2 维重构回 4 维的精度很高。这正是 PCA 的价值:以极小的信息损失换取显著的维度压缩。
应用场景:数据可视化与聚类发现
PCA 最直观的应用是数据可视化,高维数据难以直接观察其结构,但降到 2 维后绘制散点图,可以清晰地看到数据的聚类结构、异常点分布以及类别之间的关系。
下面的代码演示了一个典型场景:生成包含 3 个簇的 4 维数据,使用 PCA 降到 2 维后可视化。从散点图中可以观察到 3 个簇明显分离,这正是 PCA 在无监督学习中揭示数据结构的价值。
import numpy as np
from shared.unsupervised.pca import PCA
import matplotlib.pyplot as plt
# 生成多簇数据(3个簇,每个簇50个样本,4维特征)
X = np.vstack([
np.random.multivariate_normal([0, 0, 0, 0], np.eye(4) * 0.5, 50),
np.random.multivariate_normal([3, 3, 1, 1], np.eye(4) * 0.5, 50),
np.random.multivariate_normal([-2, 2, -1, 2], np.eye(4) * 0.5, 50)
])
# 为可视化添加颜色标签
colors = ['red'] * 50 + ['blue'] * 50 + ['green'] * 50
# PCA降维到2维(使用之前实现的PCA类)
pca = PCA(n_components=2)
X_2d = pca.fit_transform(X)
print("=== 数据可视化降维 ===")
print(f"原始维度: {X.shape[1]}")
print(f"降维后维度: 2")
print(f"累计解释比例: {pca.explained_variance_ratio_.sum():.3f}")
# 绘制散点图
plt.figure(figsize=(10, 6))
for color in ['red', 'blue', 'green']:
mask = [c == color for c in colors]
plt.scatter(X_2d[mask, 0], X_2d[mask, 1], c=color, alpha=0.6, s=50)
plt.xlabel('第一主成分 (PC1)', fontsize=12)
plt.ylabel('第二主成分 (PC2)', fontsize=12)
plt.title('PCA降维后的数据分布', fontsize=14)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
plt.close()
从散点图中可以观察到:三个簇在 2 维空间中清晰分离,红色簇位于左下区域,蓝色簇位于右上区域,绿色簇位于中间偏左。这说明原始 4 维数据的"主要结构"(3 个簇的分布)被完整保留在 2 维投影中。累计方差解释比例约为 99%,进一步印证了这一点,PCA 成功捕捉了数据的主要信息。这种可视化技术在实际场景中应用广泛:
- 客户分群分析:将用户的数十维特征(消费行为、浏览偏好等)降到 2 维,观察客户群体的自然划分。
- 异常检测:降维后远离主体的孤立点可能是异常样本(如欺诈交易、设备故障)。
- 特征有效性评估:若降维后数据呈现清晰的类别分离,说明原始特征对区分目标有效。
奇异值分解
前面详细讨论了 PCA 的数学原理,其核心是通过协方差矩阵的特征分解找到最优投影方向。如果数据矩阵本身不是方阵,是否有更通用的数学工具?答案就是奇异值分解(Singular Value Decomposition,SVD),任意一个线性变换都可以分解为"旋转—缩放—旋转"三个步骤。 将数据旋转到主成分坐标系, 沿各主成分方向进行缩放(奇异值就是缩放因子), 再旋转到最终的样本空间。这种分解方式与 PCA 的投影思想完全一致,只是视角有所差别,PCA 关注投影方向(),SVD 关注完整的变换结构(、、)。SVD 与 PCA 之间存在着深刻的内在联系,回顾 PCA 的推导过程:给定中心化后的数据矩阵 (),协方差矩阵为 ,PCA 通过对 进行特征分解得到主成分。现在考虑对 直接进行 SVD 分解:
其中 是 的正交矩阵(左奇异向量), 是 的对角矩阵(奇异值), 是 的正交矩阵(右奇异向量)。将这个分解代入协方差矩阵的定义:
这个结果揭示了两者的联系:协方差矩阵的特征向量就是 SVD 的右奇异向量 ,而特征值与奇异值的关系为 。换言之,PCA 本质上就是对数据矩阵进行 SVD 分解后取右奇异向量作为主成分方向。这种等价性并非巧合,而是线性代数中不同分解方法对同一几何结构的等价描述。尽管两者在数学上等价,但 SVD 仍然有其意义,具体有如下三点:
- 首先,SVD 直接作用于数据矩阵 ,无需显式计算协方差矩阵,这在 很大时(如图像数据)可以节省大量计算和存储。
- 其次,SVD 对矩阵形状没有限制,无论 还是 都能正常工作,而协方差矩阵的特征分解在样本数少于特征数时会出现秩亏问题。
- 最后,SVD 提供了更丰富的信息,左奇异向量 描述了样本在主成分空间中的位置,这在推荐系统、潜在语义分析等应用中具有重要价值。
奇异值是矩阵分解中产生的非负实数,它们揭示了矩阵的"能量分布"。具体来说,对于任意矩阵 (不限于方阵),其奇异值 定义为矩阵 (或 )特征值的平方根: 。其中 是 的特征值。奇异值总是非负的,习惯上按从大到小排列:。
奇异值越大,说明矩阵在该方向上蕴含的信息量或者说"能量"越大;奇异值越小,说明该方向上的信息越微弱,往往对应噪声或次要细节。这一特性使奇异值成为数据压缩、降维和噪声过滤的关键指标,只需保留较大的奇异值,就能在损失可控的前提下大幅减少数据存储量。下面用一个简单例子来演示奇异值的运用:
import numpy as np
from PIL import Image
import requests
from io import BytesIO
import matplotlib.pyplot as plt
# 从网站读取图像并转为灰度矩阵
url = "https://ai.icyfenix.cn/logo_min_size.png"
img = Image.open(BytesIO(requests.get(url, timeout=10).content)).convert("L")
A = np.array(img, dtype=float)
m, n = A.shape
print(f"原图尺寸:{m} × {n}")
print(f"原始数据量:{A.size} 个像素")
# 对图像矩阵做 SVD 分解
U, S, Vt = np.linalg.svd(A, full_matrices=False)
print(f"奇异值总数:{len(S)}")
# 用不同数量的奇异值重建图像,对比压缩效果
k_values = [5, 20, 50, len(S)]
fig, axes = plt.subplots(1, 4, figsize=(14, 4))
for ax, k in zip(axes, k_values):
# 只保留前 k 个奇异值重建图像
A_k = U[:, :k] @ np.diag(S[:k]) @ Vt[:k, :]
# 压缩存储量:U 的 m×k + S 的 k + Vt 的 k×n,原始为 m×n
compressed_size = m * k + k + k * n
ratio = compressed_size / A.size
energy = (S[:k]**2).sum() / (S**2).sum()
label = f"k = {k} | 能量 {energy:.1%} | 存储量 {ratio:.0%}"
ax.imshow(A_k, cmap="gray")
ax.set_xlabel(label, fontsize=9)
ax.set_xticks([])
ax.set_yticks([])
plt.suptitle("SVD 图像压缩:保留不同数量奇异值的重建效果", fontsize=12)
plt.tight_layout()
plt.show()
SVD 是图像压缩的基础,虽然图像矩阵包含大量数据,但其信息往往集中在少数几个主要方向上,大奇异值对应主要特征,小奇异值对应细节噪声。通过保留前 个最大奇异值,忽略其余较小的奇异值,可以用远少于原始数据的存储量重建一幅近似图像。压缩率取决于保留的奇异值数量 ,保留越多,图像质量越接近原图;保留越少,压缩率越高但细节损失越多。这种保留主要能量、舍弃次要成分的思路,与人类视觉系统对图像的认知方式天然契合。人眼对图像的整体结构、主要轮廓敏感,而对细微纹理变化相对宽容。
从上面代码的运行结果中可以直观地看到 SVD 压缩的效果:仅保留 5 个奇异值时,图像只剩模糊轮廓,但已经能辨认出大致形状;保留 20 个时细节明显恢复;保留 50 个时与原图几乎看不出差别,而存储量仅为原始数据的约 78%。值得注意的是,当 k 等于矩阵的秩(128)时,存储量反而超过 100%。这是因为完整 SVD 分解需要同时保存 、、 三个矩阵,总元素数比原始矩阵更多。SVD 压缩的优势恰恰体现在 k 远小于秩的时候,用少量奇异值就能逼近原图质量,这正是低秩近似的威力。
本章小结
降维技术的价值在于它架起了一座连接高维数据与人类认知的桥梁。在数据科学实践中,我们常常面临一个根本性的矛盾:真实世界的数据维度不断膨胀,但人类的理解能力、计算资源和可视化手段却始终受限。维度诅咒不仅仅是数学上的抽象概念,它实实在在地影响着每一个机器学习模型的性能。
更深层次地看,降维技术的思想已经超越了单纯的数据压缩范畴,渗透到了现代机器学习的方方面面。深度学习中的自编码器本质上是 PCA 的非线性扩展;词嵌入将高维的 One-Hot 编码压缩到低维稠密向量空间;图像处理中的低秩近似直接运用了奇异值分解的原理。理解降维,就是理解了如何从海量信息中提炼核心结构,如何在信息损失与计算效率之间找到平衡点,这是每一位数据从业者必须掌握的基本素养之一。
练习题
为什么 PCA 选择最大化投影方差而不是最小化投影误差?两者有什么关系?
参考答案
PCA 最大化投影方差等价于最小化重构误差。这是因为:
由于总方差是常数,最大化投影方差必然最小化重构误差。选择方差最大化作为目标函数的原因是数学推导更直接,可以转化为协方差矩阵的特征分解问题。
LDA 最多能降到多少维?为什么有这个限制?
参考答案
LDA 最多能降到 维(类别数减一)。这是因为:
类间散度矩阵 的秩最多为 (每个类别中心与全局中心的偏离,只有 个独立方向)。因此, 最多有 个非零特征值,LDA 只能选择这 个有意义的投影方向。
譬如,三分类问题最多降到 2 维,二分类问题最多降到 1 维。
假设某数据集的协方差矩阵特征值为 。若要求累计方差解释比例达到 95%,应该选择多少个主成分?
参考答案
总方差 =
累计方差解释比例计算:
- 前 1 个:
- 前 2 个:
- 前 3 个:
前 3 个主成分的累计解释比例为 97.7%,超过 95% 的阈值。因此应该选择 3 个主成分。
实现一个函数,根据目标方差解释比例自动确定主成分数量。
参考答案
import numpy as np from shared.unsupervised.pca import PCA def select_n_components(pca, target_ratio=0.95): # 根据目标方差解释比例自动确定主成分数量 cumulative = np.cumsum(pca.explained_variance_ratio_) n_components = np.argmax(cumulative >= target_ratio) + 1 return n_components # 测试 from sklearn.datasets import load_iris iris = load_iris() X = iris.data # 先用全部主成分训练 pca_full = PCA() pca_full.fit(X) # 自动选择达到95%解释比例的主成分数量 n = select_n_components(pca_full, 0.95) print(f"达到95%解释比例需要 {n} 个主成分") print(f"实际解释比例: {pca_full.explained_variance_ratio_[:n].sum():.3f}")点击 Run 按钮执行代码,点击代码区域可编辑