矩阵是向量的自然扩展,也是线性代数的核心研究对象。如果说向量是单个数据点,那么矩阵就是数据集或变换规则。本章将系统地介绍矩阵的定义、运算规则及矩阵的几何意义 —— 线性变换。
矩阵 (Matrix)是由标量按行列排列成的矩形阵列,如同向量将标量从零阶扩展到一阶,矩阵则把向量从一阶扩展到了二阶。习惯上,人们常用粗体、大写字母来表示矩阵。一个 m × n m \times n m × n A \mathbf{A} A m m m n n n m × n m \times n m × n m m m n n n 方阵 (Square Matrix),其形状为正方形。
A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] \mathbf{A} = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix} A = a 11 a 21 ⋮ a m 1 a 12 a 22 ⋮ a m 2 ⋯ ⋯ ⋱ ⋯ a 1 n a 2 n ⋮ a mn 矩阵 A \mathbf{A} A i i i j j j a i j a_{ij} a ij ( A ) i j (\mathbf{A})_{ij} ( A ) ij 2 × 3 2 \times 3 2 × 3
▶ Run
import numpy as npA = np. array( [
[ 1 , 2 , 3 ] ,
[ 4 , 5 , 6 ]
] ) print ( f"矩阵形状: { A. shape} " ) print ( f"行数: { A. shape[ 0 ] } " ) print ( f"列数: { A. shape[ 1 ] } " ) print ( f"元素 a[0,1]: { A[ 0 , 1 ] } " ) 点击 Run 按钮执行代码,点击代码区域可编辑
矩阵是机器学习和数据科学的基础性工具。可以把矩阵想象成 Excel 的数据表,通过行、列参数就能定位到数据,但它能做的远不止存储数据。这里列举一些矩阵的应用场景:
数据集表示 :矩阵是机器学习的"原材料",把矩阵想象成一张数据表格:每行是一个样本(譬如一位用户、一张图片),每列是一个特征(譬如年龄、价格、像素值)。这种结构让计算机能高效处理成千上万的数据点。
线性变换 :矩阵是数据的"转换器",把矩阵想象成一种数据操作和变形的工具,能把数据从一种形态转换成另一种。譬如把二维平面上的点旋转 45 度,或者把三维物体投影到二维屏幕,这些操作都可以用矩阵乘法表示。m × n m \times n m × n n n n m m m
权重矩阵 :矩阵是神经网络的"记忆",神经网络的核心就是权重矩阵,人们谈及大模型 8B、32B、671B 等这些百亿、千亿的参数数量,实际所说的就是权重矩阵的长度。想象大脑神经元之间的连接:有的连接强,有的弱。权重矩阵记录了这些连接强度,矩阵的每个元素 w i j w_{ij} w ij i i i j j j
协方差矩阵 :矩阵是变量间的"默契度",协方差矩阵可以回答一组变量是怎么一起变动的。它以正数表示正相关,"同进退"(气温和冰淇淋销量);以负数表示负相关,"唱反调"(海拔和气温),以接近零表示不相关,"各玩各的"(智商和鞋码)。
邻接矩阵 :矩阵是关系的"地图",社交网络、交通路线、网页链接,等都可以用邻接矩阵表示。矩阵中 a i j a_{ij} a ij i i i j j j
同向量一样,矩阵同样支持加法、数乘、乘法运算,但是会有一些前提约束:两个矩阵必须具有相同的维度(相同的行数和列数)才能够进行加法运算,两个矩阵必须满足第一个矩阵的列数必须等于第二个矩阵的行数(内维匹配)才能进行乘法运算。
矩阵加法 :矩阵相加的结果是对应元素相加:( A + B ) i j = a i j + b i j (\mathbf{A} + \mathbf{B})_{ij} = a_{ij} + b_{ij} ( A + B ) ij = a ij + b ij
交换律:A + B = B + A \mathbf{A} + \mathbf{B} = \mathbf{B} + \mathbf{A} A + B = B + A 结合律:( A + B ) + C = A + ( B + C ) (\mathbf{A} + \mathbf{B}) + \mathbf{C} = \mathbf{A} + (\mathbf{B} + \mathbf{C}) ( A + B ) + C = A + ( B + C ) 矩阵数乘 :标量与矩阵相乘,结果是原矩阵的每个元素都乘以该标量:( c A ) i j = c ⋅ a i j (c\mathbf{A})_{ij} = c \cdot a_{ij} ( c A ) ij = c ⋅ a ij
矩阵乘法 :矩阵乘法是矩阵运算的核心。设 A \mathbf{A} A m × p m \times p m × p B \mathbf{B} B p × n p \times n p × n C = A B \mathbf{C} = \mathbf{AB} C = AB m × n m \times n m × n c i j = ∑ k = 1 p a i k b k j = a i 1 b 1 j + a i 2 b 2 j + ⋯ + a i p b p j c_{ij} = \sum_{k=1}^{p} a_{ik} b_{kj} = a_{i1}b_{1j} + a_{i2}b_{2j} + \cdots + a_{ip}b_{pj} c ij = ∑ k = 1 p a ik b k j = a i 1 b 1 j + a i 2 b 2 j + ⋯ + a i p b p j C \mathbf{C} C i i i j j j A \mathbf{A} A i i i B \mathbf{B} B j j j
结合律:( A B ) C = A ( B C ) (\mathbf{AB})\mathbf{C} = \mathbf{A}(\mathbf{BC}) ( AB ) C = A ( BC ) 数乘结合律:c ( A B ) = ( c A ) B = A ( c B ) c(\mathbf{AB}) = (c\mathbf{A})\mathbf{B} = \mathbf{A}(c\mathbf{B}) c ( AB ) = ( c A ) B = A ( c B ) 分配律:A ( B + C ) = A B + A C \mathbf{A}(\mathbf{B} + \mathbf{C}) = \mathbf{AB} + \mathbf{AC} A ( B + C ) = AB + AC 但是,矩阵乘法不满足交换律,一般情况下,A B ≠ B A \mathbf{AB} \neq \mathbf{BA} AB = BA B A \mathbf{BA} BA 3 × 2 3 \times 2 3 × 2 2 × 3 2 \times 3 2 × 3 3 × 3 3 \times 3 3 × 3
A = [ 1 2 3 4 5 6 ] , B = [ 1 2 3 4 5 6 ] , A B = [ 1 ⋅ 1 + 2 ⋅ 4 1 ⋅ 2 + 2 ⋅ 5 1 ⋅ 3 + 2 ⋅ 6 3 ⋅ 1 + 4 ⋅ 4 3 ⋅ 2 + 4 ⋅ 5 3 ⋅ 3 + 4 ⋅ 6 5 ⋅ 1 + 6 ⋅ 4 5 ⋅ 2 + 6 ⋅ 5 5 ⋅ 3 + 6 ⋅ 6 ] = [ 9 12 15 19 26 33 29 40 51 ] \mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix}, \quad \mathbf{B} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}, \quad \mathbf{AB} = \begin{bmatrix} 1 \cdot 1 + 2 \cdot 4 & 1 \cdot 2 + 2 \cdot 5 & 1 \cdot 3 + 2 \cdot 6 \\ 3 \cdot 1 + 4 \cdot 4 & 3 \cdot 2 + 4 \cdot 5 & 3 \cdot 3 + 4 \cdot 6 \\ 5 \cdot 1 + 6 \cdot 4 & 5 \cdot 2 + 6 \cdot 5 & 5 \cdot 3 + 6 \cdot 6 \end{bmatrix} = \begin{bmatrix} 9 & 12 & 15 \\ 19 & 26 & 33 \\ 29 & 40 & 51 \end{bmatrix} A = 1 3 5 2 4 6 , B = [ 1 4 2 5 3 6 ] , AB = 1 ⋅ 1 + 2 ⋅ 4 3 ⋅ 1 + 4 ⋅ 4 5 ⋅ 1 + 6 ⋅ 4 1 ⋅ 2 + 2 ⋅ 5 3 ⋅ 2 + 4 ⋅ 5 5 ⋅ 2 + 6 ⋅ 5 1 ⋅ 3 + 2 ⋅ 6 3 ⋅ 3 + 4 ⋅ 6 5 ⋅ 3 + 6 ⋅ 6 = 9 19 29 12 26 40 15 33 51 矩阵外积 (Outer Product):向量外积是矩阵乘法的特例,它将一个列向量与一个行向量相乘,得到一个矩阵。设 u \mathbf{u} u m m m v \mathbf{v} v n n n u v T \mathbf{u} \mathbf{v}^T u v T m × n m \times n m × n ( u v T ) i j = u i ⋅ v j (\mathbf{u} \mathbf{v}^T)_{ij} = u_i \cdot v_j ( u v T ) ij = u i ⋅ v j v T \mathbf{v}^T v T 3 × 1 3 \times 1 3 × 1 1 × 2 1 \times 2 1 × 2 3 × 2 3 \times 2 3 × 2 u = [ 1 2 3 ] , v T = [ 4 5 ] , u v T = [ 1 ⋅ 4 1 ⋅ 5 2 ⋅ 4 2 ⋅ 5 3 ⋅ 4 3 ⋅ 5 ] = [ 4 5 8 10 12 15 ] \mathbf{u} = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}, \quad \mathbf{v}^T = \begin{bmatrix} 4 & 5 \end{bmatrix}, \quad \mathbf{u} \mathbf{v}^T = \begin{bmatrix} 1 \cdot 4 & 1 \cdot 5 \\ 2 \cdot 4 & 2 \cdot 5 \\ 3 \cdot 4 & 3 \cdot 5 \end{bmatrix} = \begin{bmatrix} 4 & 5 \\ 8 & 10 \\ 12 & 15 \end{bmatrix} u = 1 2 3 , v T = [ 4 5 ] , u v T = 1 ⋅ 4 2 ⋅ 4 3 ⋅ 4 1 ⋅ 5 2 ⋅ 5 3 ⋅ 5 = 4 8 12 5 10 15 从代数角度看,矩阵乘法运算过程是一系列繁琐的加、乘法运算,可是它的几何意义却十分简洁,就是连续的 A \mathbf{A} A B \mathbf{B} B 线性变换 一节),这是人类理解矩阵乘法的捷径,代数公式是上帝留给计算机去使用的。
另外,在讲解向量内积 时提到过,向量、矩阵的乘法根据上下文可能有不同含义,要注意通过符号写法区分。矩阵乘法的写法就是"A B \mathbf{AB} AB A ∗ B \mathbf{A} * \mathbf{B} A ∗ B A ⊙ B \mathbf{A} \odot \mathbf{B} A ⊙ B ( A ⊙ B ) i j = a i j ⋅ b i j ( 1 ≤ i ≤ m , 1 ≤ j ≤ n ) (\mathbf{A} \odot \mathbf{B})_{ij} = a_{ij} \cdot b_{ij} \quad (1 \leq i \leq m,\ 1 \leq j \leq n) ( A ⊙ B ) ij = a ij ⋅ b ij ( 1 ≤ i ≤ m , 1 ≤ j ≤ n )
除加法、数乘、乘法这些二元运算外,矩阵还有"转置 "和"求逆 "两种常见的一元运算:
矩阵的转置 (Transpose)是一种将矩阵的行列互换的操作。设 A \mathbf{A} A m × n m \times n m × n A T \mathbf{A}^T A T n × m n \times m n × m ( A T ) i j = a j i (\mathbf{A}^T)_{ij} = a_{ji} ( A T ) ij = a j i
( A T ) T = A (\mathbf{A}^T)^T = \mathbf{A} ( A T ) T = A ( A + B ) T = A T + B T (\mathbf{A} + \mathbf{B})^T = \mathbf{A}^T + \mathbf{B}^T ( A + B ) T = A T + B T ( c A ) T = c A T (c\mathbf{A})^T = c\mathbf{A}^T ( c A ) T = c A T ( A B ) T = B T A T (\mathbf{AB})^T = \mathbf{B}^T \mathbf{A}^T ( AB ) T = B T A T 尤其是第四条性质,是后续学习误差反向传播算法的理论依据,( A B ) T = B T A T (\mathbf{AB})^T = \mathbf{B}^T\mathbf{A}^T ( AB ) T = B T A T
以下是一个 3 × 3 3 \times 3 3 × 3 ( 1 , 2 , 3 ) (1, 2, 3) ( 1 , 2 , 3 ) ( 4 , 5 , 6 ) (4, 5, 6) ( 4 , 5 , 6 ) ( 7 , 8 , 9 ) (7, 8, 9) ( 7 , 8 , 9 )
A = [ 1 2 3 4 5 6 7 8 9 ] , A T = [ 1 4 7 2 5 8 3 6 9 ] \mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}, \quad \mathbf{A}^T = \begin{bmatrix} 1 & 4 & 7 \\ 2 & 5 & 8 \\ 3 & 6 & 9 \end{bmatrix} A = 1 4 7 2 5 8 3 6 9 , A T = 1 2 3 4 5 6 7 8 9 矩阵的求逆 (Inverse)是一种"撤销"原矩阵的线性变换,回到原始状态的操作。对于方阵 A \mathbf{A} A B \mathbf{B} B A B = B A = I \mathbf{AB} = \mathbf{BA} = \mathbf{I} AB = BA = I A \mathbf{A} A B \mathbf{B} B A \mathbf{A} A A − 1 \mathbf{A}^{-1} A − 1
( A − 1 ) − 1 = A (\mathbf{A}^{-1})^{-1} = \mathbf{A} ( A − 1 ) − 1 = A ( A B ) − 1 = B − 1 A − 1 (\mathbf{AB})^{-1} = \mathbf{B}^{-1} \mathbf{A}^{-1} ( AB ) − 1 = B − 1 A − 1 ( A T ) − 1 = ( A − 1 ) T (\mathbf{A}^T)^{-1} = (\mathbf{A}^{-1})^T ( A T ) − 1 = ( A − 1 ) T ( c A ) − 1 = 1 c A − 1 , c ≠ 0 (c\mathbf{A})^{-1} = \frac{1}{c}\mathbf{A}^{-1} , c \neq 0 ( c A ) − 1 = c 1 A − 1 , c = 0 c c c 1 c \frac{1}{c} c 1 以下是一个 2 × 2 2 \times 2 2 × 2
A = [ 2 1 5 3 ] , A − 1 = [ 3 − 1 − 5 2 ] , A A − 1 = [ 2 ⋅ 3 + 1 ⋅ ( − 5 ) 2 ⋅ ( − 1 ) + 1 ⋅ 2 5 ⋅ 3 + 3 ⋅ ( − 5 ) 5 ⋅ ( − 1 ) + 3 ⋅ 2 ] = [ 1 0 0 1 ] = I 2 \mathbf{A} = \begin{bmatrix} 2 & 1 \\ 5 & 3 \end{bmatrix}, \quad \mathbf{A}^{-1} = \begin{bmatrix} 3 & -1 \\ -5 & 2 \end{bmatrix}, \quad \mathbf{A} \mathbf{A}^{-1} = \begin{bmatrix} 2 \cdot 3 + 1 \cdot (-5) & 2 \cdot (-1) + 1 \cdot 2 \\ 5 \cdot 3 + 3 \cdot (-5) & 5 \cdot (-1) + 3 \cdot 2 \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = \mathbf{I}_2 A = [ 2 5 1 3 ] , A − 1 = [ 3 − 5 − 1 2 ] , A A − 1 = [ 2 ⋅ 3 + 1 ⋅ ( − 5 ) 5 ⋅ 3 + 3 ⋅ ( − 5 ) 2 ⋅ ( − 1 ) + 1 ⋅ 2 5 ⋅ ( − 1 ) + 3 ⋅ 2 ] = [ 1 0 0 1 ] = I 2 不是所有操作都可以撤销,不是所有方阵都可逆。矩阵可逆的条件,需要同时满足行列式不为零(det ( A ) ≠ 0 \det(\mathbf{A}) \neq 0 det ( A ) = 0 n × n n \times n n × n rank ( A ) = n \text{rank}(\mathbf{A}) = n rank ( A ) = n 伪逆 (Pseudoinverse)获得一个最接近的近似解。伪逆记为 A + = ( A T A ) − 1 A T \mathbf{A}^+ = (\mathbf{A}^T \mathbf{A})^{-1} \mathbf{A}^T A + = ( A T A ) − 1 A T A T A \mathbf{A}^T \mathbf{A} A T A A T A \mathbf{A}^T \mathbf{A} A T A m × n m \times n m × n n × n n \times n n × n A T \mathbf{A}^T A T
A A + A = A \mathbf{A}\mathbf{A}^+\mathbf{A} = \mathbf{A} A A + A = A A + A A + = A + \mathbf{A}^+\mathbf{A}\mathbf{A}^+ = \mathbf{A}^+ A + A A + = A + ( A A + ) T = A A + (\mathbf{A}\mathbf{A}^+)^T = \mathbf{A}\mathbf{A}^+ ( A A + ) T = A A + ( A + A ) T = A + A (\mathbf{A}^+\mathbf{A})^T = \mathbf{A}^+\mathbf{A} ( A + A ) T = A + A 不要靠记忆代数公式来理解矩阵的逆,最好是从逆矩阵的意图上去理解它(不妨看看逆矩阵性质后面的文字注释)。譬如,将矩阵的变换操作想象成你对图片的 PS 的操作,想把图片完全恢复原状这就是求逆矩阵 A − 1 \mathbf{A}^{-1} A − 1
类似地,伪逆就可以直观理解为一种"尽量还原信息"的操作,想象你用相机(A \mathbf{A} A A + \mathbf{A}^+ A +
在矩阵运算中,有一类矩阵因其简洁的结构而具有特殊的代数性质。它们就像是数字世界中的"标准件",虽然形式简单,却能简化复杂的运算、揭示问题的本质,并在求解线性方程组、坐标变换等场景中扮演关键角色。下面介绍几种最重要的特殊矩阵:
单位矩阵 (Identity Matrix):I \mathbf{I} I A I = I A = A \mathbf{AI} = \mathbf{IA} = \mathbf{A} AI = IA = A
I n = [ 1 0 ⋯ 0 0 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 ] \mathbf{I}_n = \begin{bmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \end{bmatrix} I n = 1 0 ⋮ 0 0 1 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ 1 对角矩阵 (Diagonal Matrix):对角矩阵是除主对角线外,其他元素都为 0 的方阵,对角矩阵左乘向量,相当于对向量的每个分量进行独立缩放。
D = [ d 1 0 0 0 d 2 0 0 0 d 3 ] \mathbf{D} = \begin{bmatrix} d_1 & 0 & 0 \\ 0 & d_2 & 0 \\ 0 & 0 & d_3 \end{bmatrix} D = d 1 0 0 0 d 2 0 0 0 d 3 对称矩阵 (Symmetric Matrix):对称矩阵满足 A = A T \mathbf{A} = \mathbf{A}^T A = A T a i j = a j i a_{ij} = a_{ji} a ij = a j i
正交矩阵 (Orthogonal Matrix):正交矩阵满足 Q T Q = I \mathbf{Q}^T \mathbf{Q} = \mathbf{I} Q T Q = I Q − 1 = Q T \mathbf{Q}^{-1} = \mathbf{Q}^T Q − 1 = Q T
假设你有一张印在橡皮膜上的照片,对它进行的各种操作:拉伸、旋转、剪切、翻转。只要不把膜弄皱(保持直线还是直线),不把膜撕裂(保持相邻的点仍然相邻),那么这些操作本质上就都算是线性变换。从代数角度看,线性变换是"一个矩阵乘以一个向量得到另一个向量",虽然从代数公式可以准确地计算出结果,但是并不容易理解矩阵里的数字到底代表什么?每个数字与向量元素的运算又代表了什么?所以,我们继续从几何直观上寻找突破口。
想象你站在原点,面前是坐标系和许多向量,每个向量 v \mathbf{v} v e 1 = [ 1 0 ] \mathbf{e}_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix} e 1 = [ 1 0 ] e 2 = [ 0 1 ] \mathbf{e}_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix} e 2 = [ 0 1 ]
如果变形后,e 1 \mathbf{e}_1 e 1 [ a c ] \begin{bmatrix} a \\ c \end{bmatrix} [ a c ] e 2 \mathbf{e}_2 e 2 [ b d ] \begin{bmatrix} b \\ d \end{bmatrix} [ b d ] v = [ x y ] = x e 1 + y e 2 \mathbf{v} = \begin{bmatrix} x \\ y \end{bmatrix} = x\mathbf{e}_1 + y\mathbf{e}_2 v = [ x y ] = x e 1 + y e 2
v ′ = x [ a c ] + y [ b d ] = [ a x + b y c x + d y ] \mathbf{v}' = x\begin{bmatrix} a \\ c \end{bmatrix} + y\begin{bmatrix} b \\ d \end{bmatrix} = \begin{bmatrix} ax + by \\ cx + dy \end{bmatrix} v ′ = x [ a c ] + y [ b d ] = [ a x + b y c x + d y ] 这正好就矩阵乘法的结果相吻合:
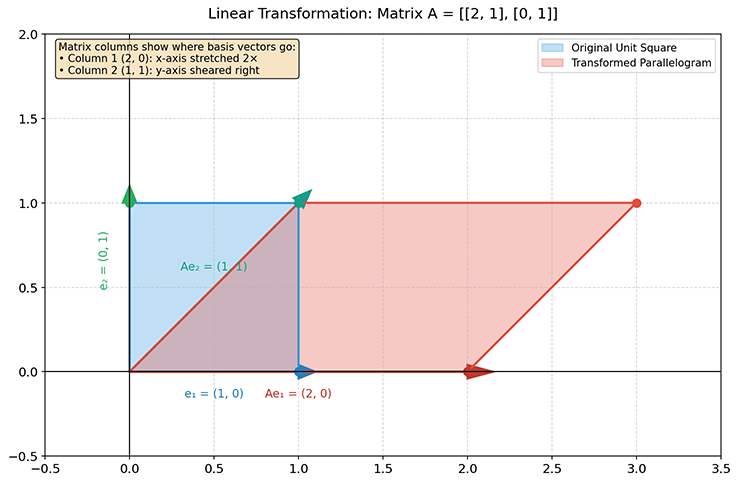
[ a b c d ] [ x y ] = [ a x + b y c x + d y ] \begin{bmatrix} a & b \\ c & d \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} ax + by \\ cx + dy \end{bmatrix} [ a c b d ] [ x y ] = [ a x + b y c x + d y ] 所以,以几何视角来看,矩阵的每一列,记录信息本质是基向量被移动到了哪里去。第一列是 x 轴单位向量的新位置,第二列是 y 轴单位向量的新位置,以此类推。矩阵乘向量,就是"把这个向量用基向量重新组装一次"。将上述思想落实到一个具体的例子,假设有一个矩阵:A = [ 2 1 0 1 ] \mathbf{A} = \begin{bmatrix} 2 & 1 \\ 0 & 1 \end{bmatrix} A = [ 2 0 1 1 ]
第一列 [ 2 0 ] \begin{bmatrix} 2 \\ 0 \end{bmatrix} [ 2 0 ] ( 1 , 0 ) (1,0) ( 1 , 0 ) ( 2 , 0 ) (2,0) ( 2 , 0 ) 第二列 [ 1 1 ] \begin{bmatrix} 1 \\ 1 \end{bmatrix} [ 1 1 ] ( 0 , 1 ) (0,1) ( 0 , 1 ) ( 1 , 1 ) (1,1) ( 1 , 1 ) 这就像是把一张正方形网格,先沿 x 方向拉伸,再向右上方剪切。如果平面中原来一个单位正方形(由 ( 0 , 0 ) , ( 1 , 0 ) , ( 1 , 1 ) , ( 0 , 1 ) (0,0), (1,0), (1,1), (0,1) ( 0 , 0 ) , ( 1 , 0 ) , ( 1 , 1 ) , ( 0 , 1 )
图:线性变换样例 - 正方形变平行四边形
至此,我们可以总结代数公式与几何直观的联系了:矩阵乘法中的每个元素 a i j a_{ij} a ij j j j i i i a , b a, b a , b c , d c, d c , d
矩阵向量积 (Matrix-Vector Product)是机器学习中最常见的运算形式,也是线性变换 的直接应用。设 A \mathbf{A} A m × n m \times n m × n v \mathbf{v} v n n n n × 1 n \times 1 n × 1 A v \mathbf{Av} Av m m m
( A v ) i = ∑ j = 1 n a i j v j = a i 1 v 1 + a i 2 v 2 + ⋯ + a i n v n (\mathbf{Av})_i = \sum_{j=1}^{n} a_{ij} v_j = a_{i1}v_1 + a_{i2}v_2 + \cdots + a_{in}v_n ( Av ) i = j = 1 ∑ n a ij v j = a i 1 v 1 + a i 2 v 2 + ⋯ + a in v n 即结果向量的第 i i i i i i 2 × 3 2 \times 3 2 × 3
A = [ 1 2 3 4 5 6 ] , v = [ 1 2 3 ] , A v = [ 1 ⋅ 1 + 2 ⋅ 2 + 3 ⋅ 3 4 ⋅ 1 + 5 ⋅ 2 + 6 ⋅ 3 ] = [ 14 32 ] \mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}, \quad \mathbf{v} = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}, \quad \mathbf{Av} = \begin{bmatrix} 1 \cdot 1 + 2 \cdot 2 + 3 \cdot 3 \\ 4 \cdot 1 + 5 \cdot 2 + 6 \cdot 3 \end{bmatrix} = \begin{bmatrix} 14 \\ 32 \end{bmatrix} A = [ 1 4 2 5 3 6 ] , v = 1 2 3 , Av = [ 1 ⋅ 1 + 2 ⋅ 2 + 3 ⋅ 3 4 ⋅ 1 + 5 ⋅ 2 + 6 ⋅ 3 ] = [ 14 32 ] ▶ Run
import numpy as npA = np. array( [
[ 1 , 2 , 3 ] ,
[ 4 , 5 , 6 ]
] ) v = np. array( [ 1 , 2 , 3 ] )
result1 = np. dot( A, v)
print ( f"np.dot 结果: { result1} " ) result2 = A @ v
print ( f"@ 运算符结果: { result2} " ) print ( f"矩阵形状: { A. shape} , 向量形状: { v. shape} , 结果形状: { result2. shape} " ) 点击 Run 按钮执行代码,点击代码区域可编辑
矩阵向量积的几何意义是把线性变换应用到具体向量上。回顾前文线性变换的几何直观 一节,矩阵的每一列记录了基向量被移动后的新位置。当矩阵乘以向量 v = ( v 1 , v 2 , … , v n ) T \mathbf{v} = (v_1, v_2, \ldots, v_n)^T v = ( v 1 , v 2 , … , v n ) T v \mathbf{v} v v j v_j v j j j j j j j
譬如,在神经网络的前向传播中,每一层的计算核心就是矩阵向量积:
h = W x + b \mathbf{h} = \mathbf{W}\mathbf{x} + \mathbf{b} h = Wx + b 其中 x \mathbf{x} x W \mathbf{W} W b \mathbf{b} b h \mathbf{h} h W \mathbf{W} W n n n m m m W \mathbf{W} W m × n m \times n m × n
机器学习领域有一句广为流传的名言:"数据决定了模型的上限,算法只是逼近这个上限"。这句话出自 2009 年 Google 研究员吴恩达(Andrew Ng)在一次机器学习讲座中的总结,它强调了数据质量对模型性能的决定性作用。而特征工程(Feature Engineering)正是提升数据质量的主要手段,它将原始数据转化为更能表达问题本质的特征表示,使模型更容易学习到数据中的规律。
特征值与特征向量的概念已经有很长的历史,18 世纪,欧拉在研究旋转刚体的运动方程时,发现了与特征值相关的数学结构 —— 刚体的旋转轴方向在变换下保持不变。这一发现当时并未引起广泛关注,但随后在微分方程、振动分析等领域反复出现。1904 年,德国数学家大卫·希尔伯特(David Hilbert)正式引入了"Eigen"这一术语(德语意为"自身的"、"固有的"),用以强调这些值和向量是矩阵固有的内在属性,而非偶然的数值巧合。中文将其译为"特征",取"特有征象"之意。
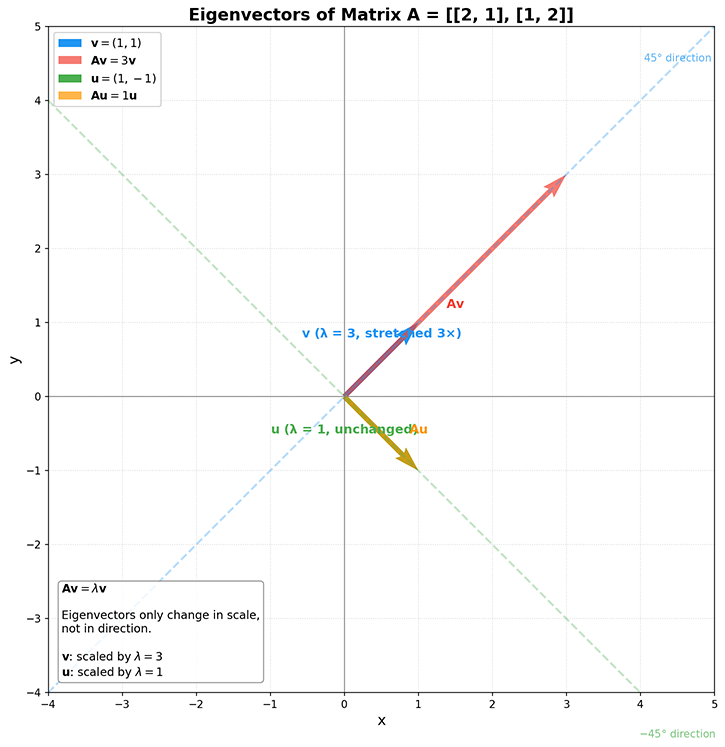
从数学定义看,对于 n × n n \times n n × n A \mathbf{A} A v \mathbf{v} v λ \lambda λ A v = λ v \mathbf{A}\mathbf{v} = \lambda\mathbf{v} Av = λ v v \mathbf{v} v A \mathbf{A} A 特征向量 ,λ \lambda λ 特征值 。用一个具体例子来理解这个定义。考虑矩阵 A = [ 2 1 1 2 ] \mathbf{A} = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix} A = [ 2 1 1 2 ] v = [ 1 1 ] \mathbf{v} = \begin{bmatrix} 1 \\ 1 \end{bmatrix} v = [ 1 1 ] A v \mathbf{A}\mathbf{v} Av
A v = [ 2 1 1 2 ] [ 1 1 ] = [ 2 ⋅ 1 + 1 ⋅ 1 1 ⋅ 1 + 2 ⋅ 1 ] = [ 3 3 ] = 3 [ 1 1 ] = 3 v \mathbf{A}\mathbf{v} = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 \cdot 1 + 1 \cdot 1 \\ 1 \cdot 1 + 2 \cdot 1 \end{bmatrix} = \begin{bmatrix} 3 \\ 3 \end{bmatrix} = 3 \begin{bmatrix} 1 \\ 1 \end{bmatrix} = 3\mathbf{v} Av = [ 2 1 1 2 ] [ 1 1 ] = [ 2 ⋅ 1 + 1 ⋅ 1 1 ⋅ 1 + 2 ⋅ 1 ] = [ 3 3 ] = 3 [ 1 1 ] = 3 v 结果 A v = 3 v \mathbf{A}\mathbf{v} = 3\mathbf{v} Av = 3 v v = [ 1 1 ] \mathbf{v} = \begin{bmatrix} 1 \\ 1 \end{bmatrix} v = [ 1 1 ] A \mathbf{A} A λ = 3 \lambda = 3 λ = 3 v \mathbf{v} v 45 ° 45° 45° A \mathbf{A} A u = [ 1 − 1 ] \mathbf{u} = \begin{bmatrix} 1 \\ -1 \end{bmatrix} u = [ 1 − 1 ]
A u = [ 2 1 1 2 ] [ 1 − 1 ] = [ 2 ⋅ 1 + 1 ⋅ ( − 1 ) 1 ⋅ 1 + 2 ⋅ ( − 1 ) ] = [ 1 − 1 ] = 1 u \mathbf{A}\mathbf{u} = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} 1 \\ -1 \end{bmatrix} = \begin{bmatrix} 2 \cdot 1 + 1 \cdot (-1) \\ 1 \cdot 1 + 2 \cdot (-1) \end{bmatrix} = \begin{bmatrix} 1 \\ -1 \end{bmatrix} = 1\mathbf{u} Au = [ 2 1 1 2 ] [ 1 − 1 ] = [ 2 ⋅ 1 + 1 ⋅ ( − 1 ) 1 ⋅ 1 + 2 ⋅ ( − 1 ) ] = [ 1 − 1 ] = 1 u 同样满足 A u = 1 u \mathbf{A}\mathbf{u} = 1\mathbf{u} Au = 1 u u \mathbf{u} u λ = 1 \lambda = 1 λ = 1 u \mathbf{u} u − 45 ° -45° − 45° A \mathbf{A} A 2 × 2 2 \times 2 2 × 2 45 ° 45° 45° − 45 ° -45° − 45°
图:特征向量的几何可视化
图中蓝色向量 v \mathbf{v} v 45 ° 45° 45° A \mathbf{A} A u \mathbf{u} u − 45 ° -45° − 45° λ \lambda λ λ > 1 \lambda > 1 λ > 1 0 < λ < 1 0 < \lambda < 1 0 < λ < 1 λ < 0 \lambda < 0 λ < 0
这一几何直觉在物理和工程中有着丰富的对应:振动系统中,特征向量指向"固有振动模式"的方向,特征值决定振动频率;量子力学里,测量算符的特征值就是可观测物理量的可能取值,特征向量对应各量子态;控制理论中,系统矩阵的特征值分布决定了系统是否稳定,所有特征值位于单位圆内意味着系统收敛,任何一个超出则会导致发散。正是这种"捕捉系统本质行为"的能力,使特征值分解成为降维、压缩、稳定性分析等任务的数学核心。
如同向量将标量从零阶扩展到一阶,矩阵将向量从一阶扩展到二阶,张量 (Tensor)更一般地扩展到了 n n n n n n n n n
阶数 名称 维度描述 NumPy 表示 0 标量 无方向,只有大小 x (标量值)1 向量 一行或一列 shape = (n,)2 矩阵 行 × 列 shape = (m, n)3 三阶张量 行 × 列 × 通道 / 深度 shape = (h, w, c)n n n n n n 维度 1 × 维度 2 × ... × 维度n n n shape = (d₁, d₂, ..., dₙ)
矩阵是张量的特例(二阶张量),因此,张量继承了矩阵的基本运算特性,支持加法、数乘,以及张量缩并(广义矩阵乘法)。张量的每个元素同样通过索引定位,如三阶张量 T \mathcal{T} T T i j k \mathcal{T}_{ijk} T ij k
当然,张量相对于矩阵,也有一些扩展之处,譬如:
多维索引 :矩阵需要两个索引定位元素(行和列),而 n n n n n n
多线性映射 :如果说矩阵乘法表示"一个线性变换接一个线性变换",那么张量缩并表示的是"多个线性变换的同时作用"。譬如,三阶张量可以同时与三个不同维度的向量进行缩并运算,描述多因素耦合的复杂变换。
坐标无关性 :张量的本质是在不同坐标系下保持不变的物理量或几何量。同一个张量在不同基底下有不同分量表示,但张量本身(作为几何对象)是不变的。这正是张量这个名字的来源 —— "张"(Stretch)表示它能在不同坐标系下"伸展"出不同的分量表示,"量"本身却保持不变。
在 NumPy 中,张量就是多维数组(ndarray),维度可以是任意正整数:
▶ Run
import numpy as npscalar = np. array( 5.0 )
print ( f"标量 shape: { scalar. shape} " ) vector = np. array( [ 1 , 2 , 3 , 4 ] )
print ( f"向量 shape: { vector. shape} " ) matrix = np. array( [ [ 1 , 2 , 3 ] , [ 4 , 5 , 6 ] ] )
print ( f"矩阵 shape: { matrix. shape} " ) tensor_3d = np. random. rand( 2 , 3 , 4 )
print ( f"三阶张量 shape: { tensor_3d. shape} " ) tensor_4d = np. random. rand( 10 , 28 , 28 , 3 )
print ( f"四阶张量 shape: { tensor_4d. shape} " ) 点击 Run 按钮执行代码,点击代码区域可编辑
深度学习中几乎所有数据都使用张量表示:输入图像是三阶或四阶张量,神经网络权重是矩阵(二阶张量),批处理数据会增加一个批次维度形成更高阶的张量。理解张量的阶数扩展,有助于在更复杂的模型架构(如卷积神经网络、Transformer)中保持对数据维度的清晰认知。
本章从矩阵这一向量的自然扩展出发,深入探讨了矩阵的代数运算、几何意义以及张量的概念延伸。
矩阵的本质与应用 。矩阵是由标量按行列排列成的矩形阵列,是数据集和变换规则的统一表示。从数据表格到权重矩阵,从协方差矩阵到邻接矩阵,矩阵贯穿机器学习的各个应用场景,它是神经网络的"记忆"存储器,是变量间"默契度"的度量工具,也是关系网络的"地图"绘制者。
矩阵运算的代数规则 。矩阵加法、数乘、乘法、转置、求逆构成矩阵运算的基础框架,其中,转置运算的行列互换特性、求逆运算的撤销还原特性是后续理解误差反向传播算法等诸多机器学习知识的理论基础。
逆矩阵与信息还原 。逆矩阵代表"撤销"变换的操作,是求解线性方程组、还原原始数据的关键工具。行列式不为零、满秩、特征值非零是矩阵可逆的等价条件。当矩阵不可逆时,伪逆提供了最小二乘意义下的最优近似解,在数据压缩和特征提取中具有重要应用。
特殊矩阵的结构优势 。单位矩阵、对角矩阵、对称矩阵、正交矩阵因其简洁的结构而具有特殊的代数性质。单位矩阵是矩阵乘法的单位元,对角矩阵实现独立缩放,对称矩阵的特征向量构成正交基,正交矩阵保持长度和角度不变,这些"标准件"在算法设计和数值计算中扮演着关键角色。
线性变换的几何直观 。矩阵的每一列记录了基向量被移动后的新位置,矩阵乘向量就是"用新基向量重新组装该向量"。从代数角度看,矩阵乘法是繁琐的元素运算;从几何角度看,它是拉伸、旋转、剪切等线性变换的简洁描述。理解这种对应关系,是掌握矩阵本质的捷径。
张量:维度的无限延伸 。张量是标量、向量、矩阵在高维空间的自然推广。从 0 阶标量到 n n n
这些概念紧密相连、层层递进:矩阵运算是操作的手段,逆矩阵是还原的工具,特殊矩阵是简化的利器,线性变换是几何的本质,张量则是维度的升华。掌握矩阵的代数运算与几何直观的双重理解,将为后续学习特征分解、奇异值分解以及神经网络优化算法奠定坚实基础。
下一章将介绍如何使用 Python 和 NumPy 进行实际的矩阵操作。
为什么矩阵乘法不满足交换律?从线性变换的角度如何理解?
参考答案 矩阵乘法表示线性变换的复合。A B \mathbf{AB} AB B \mathbf{B} B A \mathbf{A} A B A \mathbf{BA} BA A \mathbf{A} A B \mathbf{B} B 譬如,设 A \mathbf{A} A B \mathbf{B} B
计算矩阵 A = [ 1 2 3 4 5 6 ] \mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} A = [ 1 4 2 5 3 6 ] A T \mathbf{A}^T A T ( A T ) T = A (\mathbf{A}^T)^T = \mathbf{A} ( A T ) T = A
参考答案 转置: A T = [ 1 4 2 5 3 6 ] \mathbf{A}^T = \begin{bmatrix} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{bmatrix} A T = 1 2 3 4 5 6 验证:( A T ) T = [ 1 2 3 4 5 6 ] = A (\mathbf{A}^T)^T = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} = \mathbf{A} ( A T ) T = [ 1 4 2 5 3 6 ] = A
转置操作将原矩阵的行变成列、列变成行。原矩阵 2 × 3 2 \times 3 2 × 3 3 × 2 3 \times 2 3 × 2 2 × 3 2 \times 3 2 × 3
计算矩阵 A = [ 4 7 2 6 ] \mathbf{A} = \begin{bmatrix} 4 & 7 \\ 2 & 6 \end{bmatrix} A = [ 4 2 7 6 ] A − 1 \mathbf{A}^{-1} A − 1 A A − 1 = I \mathbf{A}\mathbf{A}^{-1} = \mathbf{I} A A − 1 = I
参考答案 对于 2 × 2 2 \times 2 2 × 2 [ a b c d ] \begin{bmatrix} a & b \\ c & d \end{bmatrix} [ a c b d ] 1 a d − b c [ d − b − c a ] \frac{1}{ad-bc}\begin{bmatrix} d & -b \\ -c & a \end{bmatrix} a d − b c 1 [ d − c − b a ] 计算行列式:det ( A ) = 4 × 6 − 7 × 2 = 24 − 14 = 10 \det(\mathbf{A}) = 4 \times 6 - 7 \times 2 = 24 - 14 = 10 det ( A ) = 4 × 6 − 7 × 2 = 24 − 14 = 10
由于行列式不为零,矩阵可逆:A − 1 = 1 10 [ 6 − 7 − 2 4 ] = [ 0.6 − 0.7 − 0.2 0.4 ] \mathbf{A}^{-1} = \frac{1}{10}\begin{bmatrix} 6 & -7 \\ -2 & 4 \end{bmatrix} = \begin{bmatrix} 0.6 & -0.7 \\ -0.2 & 0.4 \end{bmatrix} A − 1 = 10 1 [ 6 − 2 − 7 4 ] = [ 0.6 − 0.2 − 0.7 0.4 ]
验证:A A − 1 = [ 4 7 2 6 ] [ 0.6 − 0.7 − 0.2 0.4 ] = [ 2.4 − 1.4 − 2.8 + 2.8 1.2 − 1.2 − 1.4 + 2.4 ] = [ 1 0 0 1 ] \mathbf{A}\mathbf{A}^{-1} = \begin{bmatrix} 4 & 7 \\ 2 & 6 \end{bmatrix}\begin{bmatrix} 0.6 & -0.7 \\ -0.2 & 0.4 \end{bmatrix} = \begin{bmatrix} 2.4-1.4 & -2.8+2.8 \\ 1.2-1.2 & -1.4+2.4 \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} A A − 1 = [ 4 2 7 6 ] [ 0.6 − 0.2 − 0.7 0.4 ] = [ 2.4 − 1.4 1.2 − 1.2 − 2.8 + 2.8 − 1.4 + 2.4 ] = [ 1 0 0 1 ]
解释为什么矩阵 A = [ 1 2 2 4 ] \mathbf{A} = \begin{bmatrix} 1 & 2 \\ 2 & 4 \end{bmatrix} A = [ 1 2 2 4 ]
参考答案 代数角度:行列式 det ( A ) = 1 × 4 − 2 × 2 = 0 \det(\mathbf{A}) = 1 \times 4 - 2 \times 2 = 0 det ( A ) = 1 × 4 − 2 × 2 = 0 几何角度:观察矩阵的第二行是第一行的 2 倍,这意味着线性变换将二维平面"压扁"成一维直线。具体来说,任何向量 ( x , y ) (x, y) ( x , y ) y ′ = 2 x ′ y' = 2x' y ′ = 2 x ′
信息丢失的直观理解:就像把一张二维的照片完全压扁成一维的线条,所有垂直于该线条方向的信息都丢失了,无法通过逆向操作恢复原始的二维信息。
计算矩阵 A = [ 1 2 3 6 ] \mathbf{A} = \begin{bmatrix} 1 & 2 \\ 3 & 6 \end{bmatrix} A = [ 1 3 2 6 ] A + \mathbf{A}^+ A +
参考答案 使用伪逆公式 A + = ( A T A ) − 1 A T \mathbf{A}^+ = (\mathbf{A}^T \mathbf{A})^{-1} \mathbf{A}^T A + = ( A T A ) − 1 A T A T A = [ 1 3 2 6 ] [ 1 2 3 6 ] = [ 10 20 20 40 ] \mathbf{A}^T \mathbf{A} = \begin{bmatrix} 1 & 3 \\ 2 & 6 \end{bmatrix}\begin{bmatrix} 1 & 2 \\ 3 & 6 \end{bmatrix} = \begin{bmatrix} 10 & 20 \\ 20 & 40 \end{bmatrix} A T A = [ 1 2 3 6 ] [ 1 3 2 6 ] = [ 10 20 20 40 ]
注意 A T A \mathbf{A}^T \mathbf{A} A T A A + = 1 50 [ 1 3 2 6 ] \mathbf{A}^+ = \frac{1}{50}\begin{bmatrix} 1 & 3 \\ 2 & 6 \end{bmatrix} A + = 50 1 [ 1 2 3 6 ]
伪逆的作用:当矩阵不可逆时,伪逆提供最小二乘意义下的最优近似解。在实际应用中,伪逆可用于求解超定方程组(方程数多于变量数)的最优解,如线性回归问题。
验证矩阵 Q = [ 1 2 − 1 2 1 2 1 2 ] \mathbf{Q} = \begin{bmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} Q = [ 2 1 2 1 − 2 1 2 1 ]
参考答案 正交矩阵需要满足 Q T Q = I \mathbf{Q}^T \mathbf{Q} = \mathbf{I} Q T Q = I Q T = [ 1 2 1 2 − 1 2 1 2 ] \mathbf{Q}^T = \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} Q T = [ 2 1 − 2 1 2 1 2 1 ]
Q T Q = [ 1 2 + 1 2 − 1 2 + 1 2 − 1 2 + 1 2 1 2 + 1 2 ] = [ 1 0 0 1 ] = I \mathbf{Q}^T \mathbf{Q} = \begin{bmatrix} \frac{1}{2}+\frac{1}{2} & -\frac{1}{2}+\frac{1}{2} \\ -\frac{1}{2}+\frac{1}{2} & \frac{1}{2}+\frac{1}{2} \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} = \mathbf{I} Q T Q = [ 2 1 + 2 1 − 2 1 + 2 1 − 2 1 + 2 1 2 1 + 2 1 ] = [ 1 0 0 1 ] = I
几何意义:这是一个旋转 45° 的变换矩阵。正交矩阵的特殊性质是保持向量长度和角度不变,向量经过旋转后,其模长不变,与其他向量的夹角也不变。这就是为什么正交矩阵在坐标变换、信号处理等领域如此重要。
给定线性变换矩阵 A = [ 2 0 0 0.5 ] \mathbf{A} = \begin{bmatrix} 2 & 0 \\ 0 & 0.5 \end{bmatrix} A = [ 2 0 0 0.5 ] ( 1 , 1 ) (1, 1) ( 1 , 1 )
参考答案 变换描述:这是一个对角矩阵,表示沿坐标轴方向的独立缩放。第一列 ( 2 , 0 ) (2, 0) ( 2 , 0 ) ( 0 , 0.5 ) (0, 0.5) ( 0 , 0.5 ) 变换后的平面:原来单位正方形 [ 0 , 1 ] × [ 0 , 1 ] [0,1] \times [0,1] [ 0 , 1 ] × [ 0 , 1 ] [ 0 , 2 ] × [ 0 , 0.5 ] [0,2] \times [0,0.5] [ 0 , 2 ] × [ 0 , 0.5 ]
计算变换:A [ 1 1 ] = [ 2 0 0 0.5 ] [ 1 1 ] = [ 2 × 1 + 0 × 1 0 × 1 + 0.5 × 1 ] = [ 2 0.5 ] \mathbf{A}\begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 & 0 \\ 0 & 0.5 \end{bmatrix}\begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 \times 1 + 0 \times 1 \\ 0 \times 1 + 0.5 \times 1 \end{bmatrix} = \begin{bmatrix} 2 \\ 0.5 \end{bmatrix} A [ 1 1 ] = [ 2 0 0 0.5 ] [ 1 1 ] = [ 2 × 1 + 0 × 1 0 × 1 + 0.5 × 1 ] = [ 2 0.5 ]
向量 ( 1 , 1 ) (1, 1) ( 1 , 1 ) ( 2 , 0.5 ) (2, 0.5) ( 2 , 0.5 )
解释为什么神经网络中权重矩阵通常是矩形(非方阵)而非方阵,并举例说明。
参考答案 神经网络的权重矩阵 W \mathbf{W} W n n n m m m m × n m \times n m × n 譬如:输入层 784 维(28×28 像素图像),隐藏层 128 维,权重矩阵为 128 × 784 128 \times 784 128 × 784
非方阵的意义:
降维 :当 m < n m < n m < n 升维 :当 m > n m > n m > n 信息重构 :不同维度之间的变换让网络学习更丰富的特征表示这也是为什么神经网络能够进行特征提取和维度变换 —— 通过非方阵权重矩阵实现信息的压缩、重构和抽象。
计算三阶张量(形状为 ( 2 , 3 , 4 ) (2, 3, 4) ( 2 , 3 , 4 )
参考答案 元素总数:2 × 3 × 4 = 24 2 \times 3 \times 4 = 24 2 × 3 × 4 = 24 维度数:3(三阶张量)
图像处理中的含义:这个张量可以表示 2 张大小为 3 × 4 3 \times 4 3 × 4 3 × 4 3 \times 4 3 × 4
更常见的情况:
形状 ( H , W , C ) (H, W, C) ( H , W , C ) H H H W W W C = 3 C=3 C = 3 形状 ( N , H , W , C ) (N, H, W, C) ( N , H , W , C ) N N N 张量的多维结构让深度学习框架能够高效处理批量数据、多通道特征等复杂结构。