激活函数与损失函数
在反向传播中,我们完整推导了梯度传递的核心公式 ,其中 是激活函数的导数。这个导数决定了梯度在传递过程中的衰减或放大程度,直接影响深层网络的训练效果。另一方面,反向传播的核心是计算损失函数对参数的梯度,损失函数本身的选择和设计同样直接影响训练效果。这两个问题指向神经网络设计的两个核心组件:激活函数(Activation Functions)和损失函数(Loss Functions),激活函数为神经网络引入非线性,使网络能够学习复杂的函数关系;损失函数定义了神经网络优化的目标,衡量预测值与真实值之间的差距,引导参数更新方向。选择合适的激活函数和损失函数,是神经网络设计的两个关键决策,直接决定训练效率、收敛速度和最终性能。
本章将介绍常用激活函数和损失函数的特性、梯度特性及其对训练的影响,探讨选择策略,并通过代码实验直观展示不同函数的表现差异。
梯度消失与梯度爆炸
梯度消失(Vanishing Gradient)是指反向传播中梯度逐层衰减,传递到网络前面几层时已经十分接近 ,参数几乎不再更新。梯度消失是长期困扰深层网络训练的顽疾。不妨设想如下场景:你要从第 10 层向第 1 层传递一条信息,如果信息有衰减,譬如每经过一层消息内容被压缩(乘以小于 1 的因子),那经过 10 层后,消息就只剩 ,信息几乎消失殆尽。在梯度传递公式 里,激活函数的导数 就是那个压缩因子,误差信号 就是那封信件,误差信号越往前端传递就变得越小,这便是梯度消失。
导致梯度消失的原因主要有两个,一是权重初始化不当,权重初始值太小,导致激活值进入导数小的区域(如 Sigmoid 的两端),梯度就更小,这点可以通过选择正确的权重初始化方法(如 He 初始化、Xavier 初始化)来解决。二是激活函数导数的最大值小于 1,譬如反向传播的练习题部分推导过 Sigmoid 导数最大值为 ,每经过一层,误差信号乘以一个必定小于 1 的导数的话,层数稍多梯度就要消失。
一旦出现梯度消失,权重变化就变得极小,深层网络的前面几层参数几乎不更新,训练过程收敛极慢或停滞。同时由于前面几层没有学到有效特征,测试集的表现通常也不好。拿个具体例子来看,设 10 层网络,每层使用 Sigmoid 激活函数,导数都取恰好为最大值 (理想情况),则梯度保留比例 。经过 10 层,梯度保留比例约为 (百万分之一),前面几层梯度几乎为 。实际情况会比这更糟,因为 Sigmoid 函数的导数只会小于 。
既然梯度消失是由于连续与一个小于 1 的导数相乘而导致的,那我们选择一些导数值总是大于 1 的激活函数能解决问题吗?遗憾的是这会触发另一个问题:梯度爆炸(Exploding Gradient),它是指反向传播中梯度逐层放大,前面几层梯度极大,参数更新幅度过大,训练变得极不稳定。
梯度爆炸的成因一是权重初始化时就太大,导致梯度在传递过程中过度放大(,权重大则梯度放大),另外一个根本原因就是激活函数导数长期大于 1,连续相乘会导致参数更新幅度越来越大,损失剧烈波动,模型无法收敛,甚至导致数值溢出。相对梯度消失而言,梯度爆炸更容易发现和诊断(损失剧烈波动),但是也更危险,可能导致训练完全崩溃。
梯度消失与梯度爆炸反映了深层网络梯度传递的稳定性问题,它们很难在绝对意义上被根治(指不付出额外的代价,又能彻底解决梯度消失的问题),但是有许多工程上可行的缓解策略,这些方法将在后续章节详细展开,包括有:
- 使用恰当的激活函数:如 ReLU 系列激活函数,正数区域导数恒定为 ,避免梯度衰减和爆炸。这是最直接的解决方案,直接改变了深度学习的格局。
- 使用恰当的权重初始化:
- He 初始化(配合 ReLU):,由中国计算机科学家何凯明在 2015 年提出,专门为 ReLU 设计。
- Xavier 初始化(配合 Sigmoid / tanh):,由泽维尔·格洛罗(Xavier Glorot)在 2010 年提出。
- 批归一化(Batch Normalization):稳定激活值分布,避免进入导数小的区域。由谢尔盖·约费(Sergey Ioffe)和克里斯蒂安·塞格迪(Christian Szegedy)在 2015 年提出,目前已成为深度网络标配。
- 残差连接(Residual Connection):提供梯度旁路传递路径,即使某层梯度消失,梯度仍可通过旁路传递。由何凯明等人在 2015 年提出(ResNet),解决了数百层网络的训练问题。
- 梯度裁剪(Gradient Clipping):限制梯度范数,防止爆炸。设定阈值 ,若梯度范数超过阈值,将梯度缩放到阈值范围内。
激活函数
在构建神经网络时,一个基础认知是如果网络全部使用线性变换(),无论叠加多少层,最终仍是线性模型。线性模型的表达能力有限,无法处理图像识别、语音处理等复杂非线性问题,非线性的激活函数打破这一约束,赋予网络更强大的表达能力。激活函数本身也是一个逐渐发展的过程,从早期我们已经在线性回归中学习过的 Sigmoid 函数到现代机器学习中广泛流行的 ReLU 系列,激活函数的发展历程见证了深度学习从理论困境走向实践成功的关键转折,本章我们将系统性地介绍和对比目前常见的几种激活函数。
双曲正切函数
双曲正切函数(Hyperbolic Tangent,通常简称 tanh 函数)是 Sigmoid 的改进版本。双曲函数族(sinh、cosh、tanh)在数学中历史悠久,但将其作为神经网络激活函数使用,主要是在 1990 年代后被杰弗里·辛顿等学者推广的结果。辛顿在多层神经网络的早期研究中发现零中心输出的激活函数能显著改善训练效率,tanh 从此代替 Sigmoid 成为隐藏层的标准选择。零中心输出指激活函数的输出值以 0 为中心对称分布,正负样本数量大致平衡(如 tanh 输出范围 )。相比之下,Sigmoid 的输出恒为正(),属于非零中心输出。
用一个生活场景来解释为何为零中心输出的函数在神经网络中更具优势:假设你在调整房间空调温度,目标温度是 。但如果空调只能在 范围内调节(类似 Sigmoid 输出恒正),你能传递给网络训练的信息就只能一直是"天气太热了",网络不知道具体应该降温多少,训练呈锯齿震荡。如果空调的温度范围是 到 (类似 tanh 输出正负平衡),就可以精确给出当前温度与目标的差距,调整自然更平稳高效。
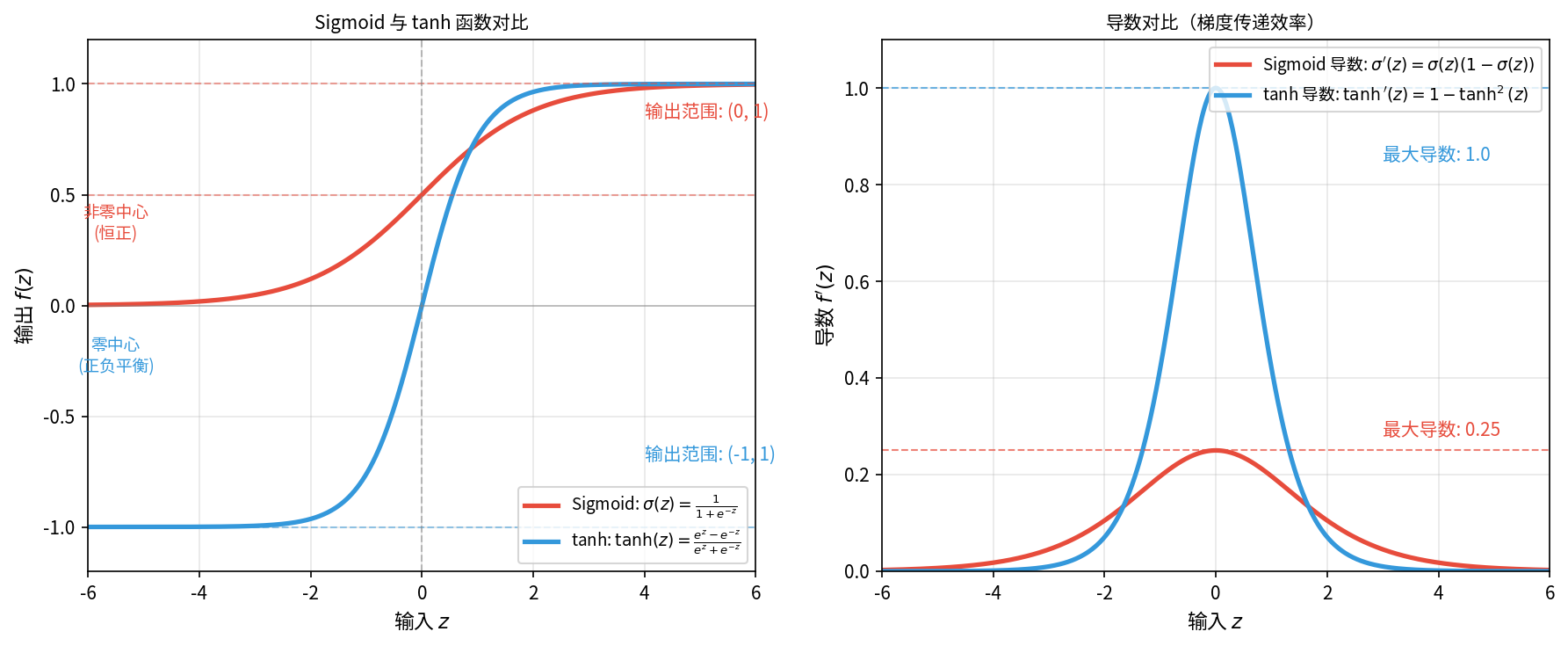
图:Sigmoid 与 tanh 函数和导数图像对比
数学上,tanh 是 Sigmoid 的线性变换版本,将 Sigmoid 放大输入(),平移输出到零中心(),就得到了 tanh,两者的函数图像如上图所示。tanh 函数的数学表达式为:
tanh 的分子部分类似"正负差",反映输入 的偏向性,分母部分类似"总和",保证分母为正。整体公式将任意实数 映射到 区间: 时 , 时 , 时
tanh 函数的导数 ,导数最大值为 (当 时),比 Sigmoid 的 大四倍。这意味着梯度传递更有效率。但 tanh 函数只是稍微缓解而非根治了梯度消失问题, 很大或很小时,导数同样趋近于 ,梯度消失问题仍然存在。Sigmoid 函数 与 tanh 函数的对比如下表所示:
| 特性 | Sigmoid | tanh |
|---|---|---|
| 输出范围 | ||
| 输出中心 | 非零中心(恒正) | 零中心(正负平衡) |
| 导数最大值 | ||
| 梯度消失 | 严重(两端导数趋近 0) | 存在(两端导数趋近 0) |
| 适用位置 | 输出层(二分类) | 隐藏层(浅层网络) |
ReLU 及其变体
传统的 Sigmoid 函数和它的改进 tanh 函数都没有能解决梯度消失问题,以至于深层网络前几层梯度几乎消失,参数难以更新。这个问题困扰了神经网络研究多年,直到一个极度简单的设计出现改变了局面。这个简单到甚至有些粗暴的设计是让函数正数区域导数恒为 1,负数区域输出为 0。想法来自 2011 年,由美国计算机科学家泽维尔·格洛罗(Xavier Glorot,当时在蒙特利尔大学、图灵奖得主约书亚·本吉奥的实验室)在论文《Deep Sparse Rectifier Neural Networks》中提出。他发现这种被称为 ReLU 的激活函数能显著改善深层网络训练效率,进而显著提升网络达到更高深度的可行性,为深度学习爆发奠定了基础。
ReLU 函数(Rectified Linear Unit,修正线性单元)是深度学习时代最流行的激活函数,它的表达式与传统的 Sigmoid 、tanh 等充斥指数运算的函数相比,显得有些格格不入,它的函数与导数为:
ReLU 设计的极其简单,正数就保持不变,负数就置零,在零点的左右导数甚至都不相等。谁能想到这个看似简陋的规则,居然一举解决了困扰神经网络多年的梯度消失问题,深度学习在 2012 年后的爆发后的成名作品 AlexNet、VGG、ResNet 等均使用 ReLU。如果把 Sigmoid 和 ReLU 想象成两根水管的话,Sigmoid 的管道逐渐变窄(导数衰减),水流越来越慢,最终几乎静止;ReLU 的管道在负数区域关闭阀门,在正数区域保持通畅(导数为 1),既不会变窄让水流减速,也不会边宽酿成洪水(梯度爆炸),深层网络前面几层也能获得足够的水压。
ReLU 的优势除了梯度完整传递,不会被衰减,使得深层网络训练变得可行外,它还有着计算高效( 只需一次比较,比指数运算快得多),同时因为正数区域是线性的,收敛更快。在 GPU 上,ReLU 的计算速度比 Sigmoid 快约 6 倍;内存开销也更低(负数部分都清零了),也间接让网络呈现稀疏状态,达成一定的自动特征选择的效果(因为不活跃的神经元对应不重要的特征)。
然而,世界上没有免费的午餐,伴随 ReLU 出现的致命问题是神经元死亡(Dead ReLU)。当输入为负()时,输出恒为 ,导数恒为 。梯度无法传递,权重永远不更新,这个神经元就相当于死亡了,网络有效容量降低。
导致神经元死亡的常见原因有如下几种,一是初始化不当,权重初始值太小,导致大量神经元一开始处于负数区域,刚刚开局就死亡了。其次是学习率过大,参数更新幅度过大,神经元冲过激活区域后死亡。譬如一个神经元原本 (激活状态),一次大幅更新后 (死亡状态),梯度为 ,后面不再有更新机会复活了。最后还有数据分布的影响,输入数据偏移,导致原本激活的神经元进入负数区域。实践中,约 10-20% 的神经元死亡是正常的,但如果超过 50%,就需要检查初始化或学习率。
针对 ReLU 的神经元死亡问题,学界给出的改进方案是负数区域不再完全置零,而是保持一个小的斜率,让梯度仍能传递。Leaky ReLU(泄漏 ReLU)由法国计算机科学家安德鲁·L·马斯(Andrew L. Maas)等人在 2013 年提出,它的函数和导数为:
其中 是小正数(通常 )。如果说 ReLU 的负数区域像水管里面紧闭的阀门,水流完全堵住;Leaky ReLU 的负数区域像一扇留了一点缝隙的阀门,水流变小( 时水流为 ),但仍能通过。这意味着神经元即使进入负数区域,梯度仍能传递,虽然传不了多远就会梯度消失,但起码还有机会复活。实践中,Leaky ReLU 在某些任务上比 ReLU 表现略好,尤其是在初始化不当或学习率较大的情况下。
德国计算机科学家德约克-阿内·克莱弗特(Djork-Arné Clevert)等人在 2015 年提出ELU 函数(Exponential Linear Unit,指数线性单元),进一步改进负数区域的处理,它的函数与导数为:
其中 是超参数(通常 )。ELU 针对 ReLU 和 Leaky ReLU 在 处存在的折角(从 突变到 和 从 突变到 )进行了修补,折角可能影响优化平滑性。ELU 在负数区域使用指数函数 平滑过渡,避免折角,有利于下一层输入分布平衡(类似 tanh 的零中心优势)
同样在 2015 年,何凯明(2015 年在微软亚洲研究院,现为 FAIR 研究员)提出 PReLU 函数(Parametric ReLU,参数化 ReLU),将 Leaky ReLU 的斜率参数化,它的函数与导数是:
其中 不再是人为设置的超参数,而是网络可学习的参数,每个神经元有独立的斜率。何凯明等人在 ResNet(深度残差网络,2015 年 ImageNet 冠军)中使用 PReLU,发现斜率通过反向传播学习,自动适应数据分布,比固定斜率更灵活。实验显示,PReLU 在 ImageNet 分类任务上比 ReLU 提升约 1% 的准确率(不要被 1% 数字误导,当年 ImageNet 分类任务冠军的错误率才 3.57%,准确率提升 1% 是一个巨大的进步)。
实践中,今天 ReLU 仍是深度网络的常用的选择,简单高效,效果良好,其他 ReLU 系列激活函数也可以按需选用,如果担心神经元死亡,使用 Leaky ReLU();如果追求零中心输出,使用 ELU;如果愿意增加参数量,使用 PReLU。随着大语言模型的兴起,Swish(2017 年谷歌提出,)和 GELU(Transformer/BERT/GPT 系列模型广泛使用)等新一代激活函数走到了舞台中央,下节将详细介绍它们的设计思想和数学特性。本节提到的 ReLU 系列激活函数各项特征对比如下表所示:
| 特性 | ReLU | Leaky ReLU | ELU | PReLU |
|---|---|---|---|---|
| 正数区域 | ||||
| 负数区域 | ||||
| 导数(正数) | ||||
| 导数(负数) | ||||
| 神经元死亡 | 有风险 | 避免 | 避免 | 避免 |
| 计算成本 | 低 | 低 | 中(指数) | 低 |
| 参数 | 无 | 固定 | 固定 | 可学习 |
GELU 与 Swish
ReLU 的硬截断设计(负数区域完全置零)带来了神经元死亡的风险,Leaky ReLU 和 ELU 分别用微小斜率和指数平滑来修补负数区域,一定程度上缓解了该风险。但将输入分为"通过"和"截断"两类,这种非此即彼的二分法与真实世界中信息的连续性始终是存在冲突的。在自然语言中,一个词对语义信息的贡献几乎不会是纯粹的"有"或"无",更多时候是多大程度上相关。大语言模型的兴起催生了对更精细激活函数的需求,GELU 和 Swish 便是这一趋势下的产物。
GELU 函数(Gaussian Error Linear Unit,高斯误差线性单元)由美国计算机科学家丹·亨德里克斯(Dan Hendrycks)和凯文·金佩尔(Kevin Gimpel)在 2016 年提出。它将 ReLU 的确定性门控替换为概率性的加权,ReLU 根据输入的正负号决定输出是 还是 ,GELU 则根据输入在标准正态分布下的累积概率来加权输出。ReLU 像一道闸门,水压为正就全开,水压为负就全关。GELU 像一个根据水压大小连续调节的阀门,水压越大开得越大,水压在零附近时只开一半,水压为负时也保留一丝缝隙。这种平滑过渡使得梯度在任意输入值下都能有效传递,不存在 ReLU 的导数突变问题。GELU 的数学定义是输入乘以标准正态分布的累积分布函数:
其中 是标准正态分布的累积分布函数(CDF), 是高斯误差函数。 很大时,,GELU 趋近于恒等函数 (类似 ReLU 的正数区域); 很小时,,GELU 趋近于 (类似 ReLU 的负数区域,但并非完全置零); 时,,输出为 。GELU 的精确形式涉及 函数,计算成本较高。实践中通常使用一个快速的 tanh 近似:
该近似与精确公式的误差在 量级,PyTorch 等框架默认的 GELU 实现就使用此近似版本。对于绝大多数应用场景,精确形式与 tanh 近似在实际效果上没有可察觉的差异。下图左边为 GELU、Swish 和 ReLU 三条曲线的对比,右边为 GELU 精确形式与 tanh 近似的对比:
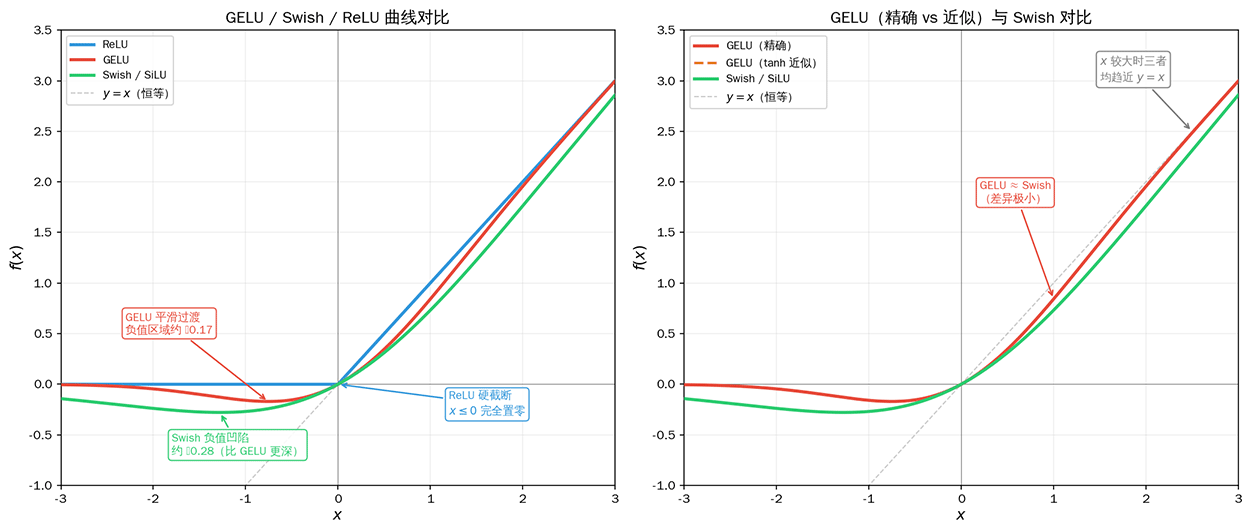
图:左为 GELU、Swish 和 ReLU 曲线对比,右为 GELU 精确形式与 tanh 近似的对比
Swish 函数由谷歌大脑团队在 2017 年的论文《Searching for Activation Functions》中提出。这篇论文本意是用自动搜索技术发现更好的激活函数,结果搜索到的最优函数恰好是 这个简洁的形式,谷歌将其命名为 Swish。有趣的是,同样的函数在亨德里克斯 2016 年的 GELU 论文中已经作为对照实验出现过(当时被称为 SiLU,即 Sigmoid Linear Unit),后来也被斯特凡·埃尔夫温(Stefan Elfwing)等人在强化学习研究中独立提出。学术界如今将 SiLU 和 Swish 视为同一函数的两个名称。Swish 的数学表达式为:
其中 就是我们熟悉的 Sigmoid 函数。Swish 可以带有一个可学习的参数 (完整形式 ), 控制门控的陡峭程度。 时退化为线性函数 ; 时即为标准 SiLU; 时趋近于 ReLU。因此 Swish 函数族可以看作在纯线性和 ReLU 之间的平滑插值。实践中绝大多数模型直接使用 的标准形式。
GELU 和 Swish 的曲线形状十分相似。两者都是处处平滑、处处可导的非单调函数,在负数区域都有一个微小的凹陷(Swish 的凹陷略深,在 处达到约 ),在正数区域都趋近于恒等函数。两者的细微差异来源于所用的概率分布不同。GELU 使用正态分布的 CDF 作为门控函数,Swish 使用 Sigmoid(逻辑分布)作为门控函数。正态分布的尾部更薄,因此 GELU 对极端负值的抑制更彻底。逻辑分布的尾部更厚,因此 Swish 在中等负值区域的抑制更缓和。在计算效率方面,Swish 需要一次 Sigmoid 计算(指数 + 除法),GELU 的精确形式需要一次 erf 计算(更昂贵),但 GELU 的 tanh 近似将成本降低到了与 Swish 相近的水平,两者在现代 GPU 上的实际运算时间差异不大。
激活函数选择策略
前面介绍了 tanh、ReLU 系以及 GELU/Swish 激活函数,加上之前已经接触过的 Sigmoid 和 Softmax,它们各有优缺点,下表给出实践中激活函数的选择策略,主要基于网络架构类型(CNN、Transformer 或浅层网络)和任务类型(分类或回归)两个维度,如下表所示:
| 场景 | 推荐激活函数 | 原因 |
|---|---|---|
| 隐藏层(CNN / 传统深度网络) | ReLU / Leaky ReLU | 缓解梯度消失,计算高效,配合批归一化效果稳定 |
| 隐藏层(Transformer 编码器) | GELU | 平滑梯度流,无神经元死亡,匹配残差连接和层归一化 |
| 隐藏层(Transformer 解码器 / LLM) | Swish(SwiGLU 门控) | 门控机制选择性抑制无关特征,困惑度更低 |
| 隐藏层(浅层网络) | tanh / ReLU | 浅层网络梯度消失问题不严重 |
| 输出层(二分类) | Sigmoid | 输出概率,符合二分类语义 |
| 输出层(多分类) | Softmax | 输出概率分布,符合多分类语义 |
| 输出层(回归) | Linear(无激活) | 输出无范围限制 |
激活函数实践
前面的理论分析反复强调:Sigmoid 存在严重的梯度消失问题,ReLU 能缓解梯度消失但可能导致神经元死亡,GELU 和 Swish 以概率性平滑门控替代硬截断。本节通过代码实验验证,构建一个 10 层深度网络,每层 64 个神经元,使用相同输入和输出梯度,对比 Sigmoid、tanh、ReLU、Leaky ReLU、GELU、Swish 在梯度传递和神经元激活方面的表现。同时统计各层负值输出的比例,对比不同激活函数对神经元抑制行为的差异。
import numpy as np
import matplotlib.pyplot as plt
class DeepNetwork:
"""
深层神经网络,用于演示激活函数的影响
"""
def __init__(self, n_layers, n_neurons, activation='relu'):
self.n_layers = n_layers
self.n_neurons = n_neurons
self.activation = activation
# 初始化权重
np.random.seed(42)
self.weights = []
self.biases = []
# 根据激活函数选择初始化策略
if activation in ['relu', 'leaky_relu', 'gelu', 'swish']:
scale_factor = np.sqrt(2.0) # He初始化
else:
scale_factor = np.sqrt(1.0) # Xavier初始化
for i in range(n_layers):
w = np.random.randn(n_neurons, n_neurons) * scale_factor / np.sqrt(n_neurons)
b = np.zeros((n_neurons, 1))
self.weights.append(w)
self.biases.append(b)
def _apply_activation(self, Z):
"""应用激活函数"""
if self.activation == 'sigmoid':
Z = np.clip(Z, -500, 500)
return 1 / (1 + np.exp(-Z))
elif self.activation == 'tanh':
return np.tanh(Z)
elif self.activation == 'relu':
return np.maximum(0, Z)
elif self.activation == 'leaky_relu':
return np.where(Z > 0, Z, 0.01 * Z)
elif self.activation == 'gelu':
# GELU tanh 近似(与 PyTorch 默认行为一致)
alpha = np.sqrt(2.0 / np.pi)
return 0.5 * Z * (1.0 + np.tanh(alpha * (Z + 0.044715 * Z**3)))
elif self.activation == 'swish':
# Swish / SiLU: z * sigmoid(z)
return Z / (1.0 + np.exp(-Z))
elif self.activation == 'linear':
return Z
else:
raise ValueError(f"Unknown activation: {self.activation}")
def _activation_derivative(self, Z, A):
"""计算激活函数导数"""
if self.activation == 'sigmoid':
return A * (1 - A)
elif self.activation == 'tanh':
return 1 - A ** 2
elif self.activation == 'relu':
return (Z > 0).astype(float)
elif self.activation == 'leaky_relu':
return np.where(Z > 0, 1.0, 0.01)
elif self.activation == 'gelu':
# GELU tanh 近似的导数
alpha = np.sqrt(2.0 / np.pi)
inner = alpha * (Z + 0.044715 * Z**3)
t = np.tanh(inner)
sech2 = 1.0 - t ** 2
return 0.5 * (1.0 + t) + 0.5 * Z * sech2 * alpha * (1.0 + 3.0 * 0.044715 * Z**2)
elif self.activation == 'swish':
# Swish 导数: sigma(z) * (1 + z * (1 - sigma(z)))
sigma = 1.0 / (1.0 + np.exp(-Z))
return sigma * (1.0 + Z * (1.0 - sigma))
elif self.activation == 'linear':
return np.ones_like(Z)
else:
raise ValueError(f"Derivative not implemented for: {self.activation}")
def forward(self, X):
"""前向传播,存储中间结果"""
self.activations = [X]
self.pre_activations = []
A = X
for i in range(self.n_layers):
Z = self.weights[i] @ A + self.biases[i]
self.pre_activations.append(Z)
A = self._apply_activation(Z)
self.activations.append(A)
return A
def backward(self, grad_output):
"""反向传播,返回各层梯度范数"""
gradient_norms = []
delta = grad_output
for i in range(self.n_layers - 1, -1, -1):
# 计算当前层的梯度范数
grad_norm = np.linalg.norm(delta)
gradient_norms.append(grad_norm)
# 传递到上一层
if i > 0:
delta = self.weights[i].T @ delta
delta = delta * self._activation_derivative(
self.pre_activations[i-1],
self.activations[i]
)
return gradient_norms[::-1] # 反转,使顺序从前向后
# 实验:不同激活函数在深层网络中的梯度传递
print("=" * 60)
print("实验:激活函数对梯度传递的影响")
print("=" * 60)
print()
# 创建10层深度网络
n_layers = 10
n_neurons = 64
activations = ['sigmoid', 'tanh', 'relu', 'leaky_relu', 'gelu', 'swish']
activation_colors = ['#e74c3c', '#3498db', '#2ecc71', '#f39c12', '#9b59b6', '#1abc9c']
activation_labels = ['Sigmoid', 'tanh', 'ReLU', 'Leaky ReLU', 'GELU', 'Swish']
# 生成输入和输出梯度
X = np.random.randn(n_neurons, 100) # 100个样本
grad_output = np.random.randn(n_neurons, 100) # 输出层梯度
# 测试各激活函数
all_gradient_norms = []
for activation in activations:
network = DeepNetwork(n_layers, n_neurons, activation)
network.forward(X)
gradient_norms = network.backward(grad_output)
all_gradient_norms.append(gradient_norms)
# 显示完整梯度信息(注意:反向传播从输出层往输入层传递)
print(f"{activation:12s}: 反向传播梯度范数变化")
print(f" 输出层起点: {gradient_norms[-1]:.6f}")
print(f" 传至中间层: {gradient_norms[4]:.6f}")
print(f" 传至输入层: {gradient_norms[0]:.6f}")
print(f" 梯度保留比例: {gradient_norms[0]/gradient_norms[-1]:.6f} (越小说明梯度消失越严重)")
print()
print()
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 图1:梯度范数随层数变化(对数刻度)
ax1 = axes[0]
for i, (grads, color, label) in enumerate(zip(all_gradient_norms, activation_colors, activation_labels)):
ax1.semilogy(range(1, n_layers + 1), grads, 'o-', color=color,
linewidth=2, markersize=6, label=label)
ax1.set_xlabel('层索引(从输入层到输出层)', fontsize=11)
ax1.set_ylabel('梯度范数(对数刻度)', fontsize=11)
ax1.set_title('梯度传递:不同激活函数对比', fontsize=12)
ax1.legend(loc='upper right')
ax1.grid(True, alpha=0.3)
# 图2:负值输出比例对比(抑制效应)
ax2 = axes[1]
# 重新运行前向传播,收集激活值统计
activation_stats = []
for activation in activations:
network = DeepNetwork(n_layers, n_neurons, activation)
network.forward(X)
# 统计各层激活值:负值输出比例、均值、标准差
negative_ratios = []
means = []
stds = []
for i, A in enumerate(network.activations[1:]): # 跳过输入层
# 统计负值输出比例(反映不同激活函数对神经元的"抑制"程度)
negative_ratio = np.mean(A < 0)
negative_ratios.append(negative_ratio)
means.append(np.mean(A))
stds.append(np.std(A))
activation_stats.append({
'activation': activation,
'negative_ratios': negative_ratios,
'means': means,
'stds': stds
})
# 绘制 ReLU、Leaky ReLU、GELU、Swish 的负值输出比例
# ReLU: 负面输入全部置零,负值输出比例恒为 0(无抑制,直接截断)
# Leaky ReLU: 负面输入产生微小负值输出(α=0.01),负值输出比例 ≈ 负面输入比例
# GELU: 仅在 z≈-0.17 附近产生微小负值(极弱的抑制)
# Swish: 在 z≈-1.28 附近产生较深负值凹陷(更强的抑制效果)
plot_activations = ['relu', 'leaky_relu', 'gelu', 'swish']
plot_colors = ['#2ecc71', '#f39c12', '#9b59b6', '#1abc9c']
plot_labels = ['ReLU', 'Leaky ReLU', 'GELU', 'Swish']
x_positions = np.arange(1, n_layers + 1)
n_bars = len(plot_activations)
bar_width = 0.2
for idx, (act_name, color, label) in enumerate(zip(plot_activations, plot_colors, plot_labels)):
# 找到对应的 stats
act_idx = activations.index(act_name)
stats = activation_stats[act_idx]
offset = (idx - (n_bars - 1) / 2) * bar_width
ax2.bar(x_positions + offset, stats['negative_ratios'],
width=bar_width, color=color, alpha=0.75, label=label)
ax2.set_xlabel('层索引', fontsize=11)
ax2.set_ylabel('负值输出比例', fontsize=11)
ax2.set_title('激活函数抑制效应对比:负值输出比例', fontsize=12)
ax2.legend(loc='upper right')
ax2.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
plt.close()
损失函数
激活函数决定网络的非线性表达能力,损失函数则决定网络的优化目标。如果把训练神经网络比作一场越野行军,激活函数是路线上的弯道,决定能否到达复杂目的地,损失函数则是目的导航,决定往哪里行进。损失函数衡量预测值与真实值之间的差距,引导参数更新方向,不同的任务类型(回归、分类)需要不同的损失函数,在前面学习线性回归时,引入过最小二乘法和均方误差,在逻辑回归中,又引入了交叉熵损失,还有支持向量机里的 Hinge 损失。本节我们会系统性地总结对比这些常见的损失函数,并分析它们的选择策略与使用场景。
回归损失
回归问题的目标是预测连续数值,如房价预测、温度预测、销量预测等。度量连续值的损失,最直接的想法是计算预测值与真实值的差距,差距越大惩罚越重。均方误差(Mean Squared Error, MSE)采用这一思路,将差距平方后求平均:
其中 是真实值, 是预测值。平方有两个作用,一是保证结果为正,二是放大误差的影响,误差翻倍,惩罚翻四倍。MSE 的数学性质良好,是凸函数,梯度下降可收敛到全局最优,没有局部极小值陷阱。梯度 与误差成正比,大误差时梯度大(参数快速纠正),小误差时梯度小(精细调整)。放大惩罚的特性一方面令 MSE 对大误差敏感,能快速纠正明显错误,但另一方面,少数极端异常值会主导整个损失函数,导致模型容易迁就异常值,偏离大多数正常数据的规律。
如果数据中存在一定的异常值数据,那使用平均绝对误差(Mean Absolute Error, MAE)会是一个替代选择,它的数学表达为:
MAE 用绝对值而非平方,误差 10 的惩罚仅仅是误差 1 的 10 倍(线性),而 MSE 中误差 10 的惩罚是误差 1 的 100 倍(平方),这样异常值在 MAE 中影响相对有限。MAE 的梯度恒定为 (取决于误差方向),不随误差大小变化,会带来一个副作用,小误差时梯度仍然较大,可能导致收敛震荡,不像 MSE 在小误差时梯度自动减小,平稳收敛。此外,MAE 在 处不可导(梯度从 突变到 ),优化需要使用次梯度处理。
MSE 对异常值敏感,MAE 在零点不可导,结合两者优点,瑞士统计学家彼得·胡贝尔(Peter Huber)在 1964 年提出 Huber 损失,在小误差区域使用 MSE(平滑、梯度递减),在大误差区域使用 MAE(线性、鲁棒),它的数学表达是:
其中 是阈值参数(通常 )。两段函数在 处平滑过渡(函数值相等、导数相等),处处可导,对优化过程友好。
三种回归损失函数的特性对比如下表所示,实践中,数据干净无异常值时首选 MSE;数据有异常值时选择 MAE 或 Huber 损失;追求平衡时 Huber 损失是最稳妥的选择。
| 特性 | MSE | MAE | Huber |
|---|---|---|---|
| 惩罚方式 | 二次(平方) | 纯线性 | 小误差二次,大误差线性 |
| 异常值敏感度 | 高(敏感) | 低(鲁棒) | 中(平衡) |
| 梯度变化 | 与误差成正比 | 恒定 | 小误差递减,大误差恒定 |
| 优化难度 | 易(凸函数) | 中(零点不可导) | 易(处处可导) |
分类损失
回归问题预测数值,分类问题预测类别。类别是离散的信息(如"猫、狗、鸟"),需要专门的损失函数交叉熵损失(Cross-Entropy Loss)。它以信息论中概率越小的事件发生时信息量越大的观点为基础,度量两个概率分布之间的差异,数学表达为(具体见逻辑回归中的推导):
其中 是真实分布, 是预测分布。当 (预测完全正确),交叉熵等于熵 达到最小值;预测越偏离真实分布,交叉熵越大。在机器学习中,真实分布 由训练数据给定(通常是 One-Hot 编码),预测分布 由模型输出(Softmax 或 Sigmoid),训练目标就是最小化交叉熵,使预测分布逼近真实分布。
二分类问题只有两个类别(如"是否为垃圾邮件"),输出一个概率值 (通常由 Sigmoid 输出)。这种情况下通常采用二分类交叉熵损失(Binary Cross-Entropy Loss,简称 BCE):
其中 是真实标签, 是预测概率。公式的 当 (正类)时有效,预测越接近 1, 越小; 当 (负类)时有效,预测越接近 0,损失越小。两项加权求和,形成类似开关的机制,自动选择对应类别的惩罚项。举个具体数值例子,预测正确时(如 ,),损失约 ;预测错误时(如 ,),损失约 。错误惩罚约 20 倍,这正是函数期望的行为,严厉惩罚明显错误,温和奖励正确预测。
多分类问题有多个类别(如手写数字识别 0-9 共 10 类),输出多个概率值(Softmax 输出概率分布),这时候通常采用多分类交叉熵损失(Categorical Cross-Entropy Loss,简称 CE):
其中 是真实标签的 One-Hot 编码(只有真实类别 ), 是预测概率。由于 One-Hot 编码中只有一个 ,公式简化为:
即损失等于真实类别预测概率的负对数。预测真实类别的概率越高,损失越低。用考试类比,多分类交叉熵像一道选择题,答对(选择正确类别)得分高(损失低),答错(选择错误类别)得分低(损失高),部分正确(选择正确类别但置信度低)得分中等。这与 MSE 将类别编号当作数值的做法完全不同,后者会把"选择类别 3"和"选择类别 5"的距离当作数值差距(差值为 2),语义模糊且不合理。
交叉熵损失是训练时优化的目标函数,而评估分类模型性能时,还需要一个与阈值无关的指标来衡量模型的整体排序能力。曲线下面积(Area Under the Curve,AUC)是最常用的分类评估指标之一。ROC 曲线以假阳性率(False Positive Rate,,即被错误判为正类的负样本比例)为横轴,真阳性率(True Positive Rate,,即被正确判为正类的正样本比例)为纵轴,描绘了分类阈值从 0 到 1 变化时两者之间的权衡关系。AUC 的数学定义为:
直观上,AUC 等于随机抽取一个正样本和一个负样本,模型给正样本的打分高于负样本的概率:
AUC 的取值范围为 ,0.5 表示模型没有区分能力(等同于随机猜测),1.0 表示完美排序。与 BCE 相比,两者的趋势方向完全一致。BCE 低的模型通常 AUC 也高,因为交叉熵的梯度推动模型拉开正负样本的预测概率差距。但二者的关注点有所不同,BCE 衡量概率校准度(Calibration),要求预测概率值本身准确。AUC 衡量区分度(Discrimination),只关心正负样本的排序是否正确,不关心概率数值是否精准。譬如,一个模型将正样本预测为 0.6、负样本预测为 0.4,AUC 为 1.0(排序正确),但若真实概率应为 0.9 和 0.1,BCE 就会偏高(概率值不够极端)。BCE 是训练目标,AUC 是评估指标,实践中常同时关注两者,用 BCE 训练,用 AUC 评估排序质量。
Hinge 损失
前面介绍的损失函数用于神经网络训练。本节介绍一种用于支持向量机的损失函数 Hinge 损失,它体现了最大间隔原则的优化思想。支持向量机的核心思想是寻找最大间隔分类边界,不仅要求分类正确,还要求分类边界与两类样本保持足够距离,提高泛化能力。Hinge 损失(直译过来是合页损失,得名于形状像门铰链)体现这一思想:
其中 是真实标签(注意 SVM 使用 编码而非 ), 是预测值。公式的 是标签与预测的乘积,预测正确且同号时乘积为正; 要求 (不仅是分类正确,还要置信度足够); 保证损失非负。照例用具体数值验证一下,当 , 时,,损失为 0;当 , 时,,损失为 。只有当预测正确且置信度足够,损失才为零;否则产生损失,这体现了函数鼓励模型学习更大的分类间隔。
神经网络中很少直接使用 Hinge 损失,因为 Cross-Entropy 的梯度特性更适合梯度下降优化。但 Hinge 损失的最大间隔思想影响了神经网络的设计,衍生出如 Large Margin Softmax Loss、Triplet Loss 等损失函数,在人脸识别、度量学习等领域有应用。
损失函数选择策略
前面总结了回归损失(MSE、MAE、Huber)和分类损失(Cross-Entropy、Hinge),下表基于任务类型和数据特征,给出选择策略:
| 任务类型 | 推荐损失函数 | 输出层激活 | 选择原因 |
|---|---|---|---|
| 回归(无异常值) | MSE | Linear | 数据干净,MSE 收敛快 |
| 回归(有异常值) | MAE / Huber | Linear | 异常值鲁棒,不过度迁就 |
| 二分类 | Binary Cross-Entropy | Sigmoid | 梯度计算高效,避免消失 |
| 多分类 | Categorical Cross-Entropy | Softmax | 梯度计算高效,概率语义清晰 |
| 多标签分类 | Binary Cross-Entropy(每类) | Sigmoid | 每个标签独立二分类 |
损失函数实践
前面的理论分析得出了各类损失函数的特点:MSE 对异常值敏感,MAE 对异常值鲁棒,Cross-Entropy 比 MSE 更适合分类。本节通过代码实验验证,对比不同损失函数在回归和分类任务中的表现。
实验一:对比 MSE、MAE、Huber Loss 对异常值的不同表现。MSE 对异常值敏感,拟合线应该偏离理想线,MAE 对异常值鲁棒,拟合线接近理想线,Huber Loss 平衡两者,效果适中。
import numpy as np import matplotlib.pyplot as plt # 生成回归数据(包含异常值) n_samples = 50 # 正常数据 X_normal = np.linspace(0, 10, n_samples) y_normal = 2 * X_normal + 1 + np.random.randn(n_samples) * 0.5 # 添加几个异常值 n_outliers = 5 outlier_indices = np.random.choice(n_samples, n_outliers, replace=False) y_normal[outlier_indices] += np.random.randn(n_outliers) * 15 # 大偏差 X = X_normal y_true = y_normal # 定义损失函数 def mse_loss(y_pred, y_true): return np.mean((y_pred - y_true) ** 2) def mae_loss(y_pred, y_true): return np.mean(np.abs(y_pred - y_true)) def huber_loss(y_pred, y_true, delta=1.0): diff = np.abs(y_pred - y_true) return np.mean(np.where(diff <= delta, 0.5 * diff ** 2, delta * diff - 0.5 * delta ** 2)) # 简单线性回归(使用梯度下降) class LinearRegression: def __init__(self, loss_type='mse', learning_rate=0.01, n_iterations=1000, delta=1.0): self.loss_type = loss_type self.lr = learning_rate self.n_iter = n_iterations self.delta = delta self.w = None self.b = None self.loss_history = [] def fit(self, X, y): # 初始化参数 self.w = 0.0 self.b = 0.0 for i in range(self.n_iter): # 预测 y_pred = self.w * X + self.b # 计算损失 if self.loss_type == 'mse': loss = mse_loss(y_pred, y) elif self.loss_type == 'mae': loss = mae_loss(y_pred, y) elif self.loss_type == 'huber': loss = huber_loss(y_pred, y, self.delta) self.loss_history.append(loss) # 计算梯度 if self.loss_type == 'mse': dw = 2 * np.mean((y_pred - y) * X) db = 2 * np.mean(y_pred - y) elif self.loss_type == 'mae': dw = np.mean(np.sign(y_pred - y) * X) db = np.mean(np.sign(y_pred - y)) elif self.loss_type == 'huber': diff = y_pred - y indicator = np.where(np.abs(diff) <= self.delta, diff, self.delta * np.sign(diff)) dw = np.mean(indicator * X) db = np.mean(indicator) # 更新参数 self.w -= self.lr * dw self.b -= self.lr * db return self def predict(self, X): return self.w * X + self.b # 训练三个模型 models = { 'MSE': LinearRegression(loss_type='mse', learning_rate=0.01, n_iterations=500), 'MAE': LinearRegression(loss_type='mae', learning_rate=0.01, n_iterations=500), 'Huber': LinearRegression(loss_type='huber', learning_rate=0.01, n_iterations=500, delta=5.0) } for name, model in models.items(): model.fit(X, y_true) print(f"{name}: w={model.w:.3f}, b={model.b:.3f}, 最终损失={model.loss_history[-1]:.3f}") # 可视化 fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # 图1:拟合结果对比 ax1 = axes[0] ax1.scatter(X, y_true, c=['red' if i in outlier_indices else 'blue' for i in range(n_samples)], alpha=0.6, label='数据点(红色为异常值)') for name, model in models.items(): y_pred = model.predict(X) ax1.plot(X, y_pred, linewidth=2, label=f'{name}: y={model.w:.2f}x+{model.b:.2f}') # 理想直线(无异常值影响) y_ideal = 2 * X + 1 ax1.plot(X, y_ideal, 'g--', linewidth=2, label='理想: y=2x+1') ax1.set_xlabel('X', fontsize=11) ax1.set_ylabel('y', fontsize=11) ax1.set_title('回归损失函数对比:异常值影响', fontsize=12) ax1.legend(loc='upper left') ax1.grid(True, alpha=0.3) # 图2:损失变化 ax2 = axes[1] for name, model in models.items(): ax2.plot(model.loss_history, linewidth=2, label=name) ax2.set_xlabel('迭代次数', fontsize=11) ax2.set_ylabel('损失值', fontsize=11) ax2.set_title('训练过程损失变化', fontsize=12) ax2.legend() ax2.grid(True, alpha=0.3) plt.tight_layout() plt.show() plt.close()点击 Run 按钮执行代码,点击代码区域可编辑实验二:对比 Cross-Entropy 和 MSE 在二分类中的收敛效率。Cross-Entropy 收敛更快,效率更高;MSE 在分类中梯度消失问题导致收敛缓慢。
import numpy as np import matplotlib.pyplot as plt from matplotlib.lines import Line2D # 生成二分类数据 n_class_samples = 100 # 类别0 X0 = np.random.randn(n_class_samples, 2) + np.array([-2, -2]) y0 = np.zeros(n_class_samples) # 类别1 X1 = np.random.randn(n_class_samples, 2) + np.array([2, 2]) y1 = np.ones(n_class_samples) X_class = np.vstack([X0, X1]) y_class = np.hstack([y0, y1]) # 简单逻辑回归 class LogisticRegression: def __init__(self, loss_type='ce', learning_rate=0.1, n_iterations=1000): self.loss_type = loss_type self.lr = learning_rate self.n_iter = n_iterations self.w = None self.b = None self.loss_history = [] def sigmoid(self, z): z = np.clip(z, -500, 500) return 1 / (1 + np.exp(-z)) def fit(self, X, y): n_samples, n_features = X.shape self.w = np.zeros(n_features) self.b = 0.0 for i in range(self.n_iter): # 预测 z = X @ self.w + self.b y_pred = self.sigmoid(z) # 计算损失 if self.loss_type == 'ce': eps = 1e-15 y_pred = np.clip(y_pred, eps, 1 - eps) loss = -np.mean(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred)) elif self.loss_type == 'mse': loss = np.mean((y - y_pred) ** 2) self.loss_history.append(loss) # 计算梯度 if self.loss_type == 'ce': # Cross-Entropy + Sigmoid 的简化梯度 dz = y_pred - y elif self.loss_type == 'mse': # MSE + Sigmoid 的梯度 dz = 2 * (y_pred - y) * y_pred * (1 - y_pred) dw = np.mean(dz.reshape(-1, 1) * X, axis=0) db = np.mean(dz) # 更新参数 self.w -= self.lr * dw self.b -= self.lr * db return self def predict_proba(self, X): z = X @ self.w + self.b return self.sigmoid(z) def predict(self, X): return (self.predict_proba(X) > 0.5).astype(int) # 训练两个模型 model_ce = LogisticRegression(loss_type='ce', learning_rate=0.1, n_iterations=500) model_mse = LogisticRegression(loss_type='mse', learning_rate=0.1, n_iterations=500) model_ce.fit(X_class, y_class) model_mse.fit(X_class, y_class) print(f"Cross-Entropy: 准确率 {np.mean(model_ce.predict(X_class) == y_class):.2%}") print(f"MSE: 准确率 {np.mean(model_mse.predict(X_class) == y_class):.2%}") # 可视化 fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # 图1:决策边界 ax1 = axes[0] scatter0 = ax1.scatter(X0[:, 0], X0[:, 1], c='blue', alpha=0.6, label='类别0') scatter1 = ax1.scatter(X1[:, 0], X1[:, 1], c='red', alpha=0.6, label='类别1') # 绘制决策边界 x_min, x_max = X_class[:, 0].min() - 1, X_class[:, 0].max() + 1 y_min, y_max = X_class[:, 1].min() - 1, X_class[:, 1].max() + 1 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100)) grid = np.column_stack([xx.ravel(), yy.ravel()]) Z_ce = model_ce.predict_proba(grid).reshape(xx.shape) Z_mse = model_mse.predict_proba(grid).reshape(xx.shape) # 绘制决策边界(contour 不支持 label 参数,使用代理 artist) ax1.contour(xx, yy, Z_ce, levels=[0.5], colors='green', linewidths=2, linestyles='-') ax1.contour(xx, yy, Z_mse, levels=[0.5], colors='orange', linewidths=2, linestyles='--') # 创建代理 artist 用于 legend(contour 不支持 label 参数) ce_line = Line2D([0], [0], color='green', linewidth=2, linestyle='-', label='CE边界') mse_line = Line2D([0], [0], color='orange', linewidth=2, linestyle='--', label='MSE边界') ax1.legend(handles=[scatter0, scatter1, ce_line, mse_line], loc='upper left') ax1.set_xlabel('x1', fontsize=11) ax1.set_ylabel('x2', fontsize=11) ax1.set_title('分类损失函数对比:决策边界', fontsize=12) ax1.grid(True, alpha=0.3) # 图2:损失变化 ax2 = axes[1] ax2.plot(model_ce.loss_history, linewidth=2, color='green', label='Cross-Entropy') ax2.plot(model_mse.loss_history, linewidth=2, color='orange', label='MSE') ax2.set_xlabel('迭代次数', fontsize=11) ax2.set_ylabel('损失值', fontsize=11) ax2.set_title('训练过程损失变化', fontsize=12) ax2.legend() ax2.grid(True, alpha=0.3) plt.tight_layout() plt.show() plt.close()点击 Run 按钮执行代码,点击代码区域可编辑
本章小结
本章详细介绍了神经网络的激活函数和损失函数两大核心组件:
激活函数为神经网络引入非线性,打破线性约束,赋予网络强大的表达能力。隐藏层首选 ReLU 系列激活函数(ReLU、Leaky ReLU),缓解梯度消失问题,计算高效。在 Transformer 和大语言模型中,GELU 和 Swish 以概率性平滑门控替代硬截断,为深度残差网络提供更稳定的梯度流和内置正则化效果。输出层根据任务类型选择:二分类用 Sigmoid,多分类用 Softmax,回归用 Linear(无激活)。
损失函数定义了神经网络优化的目标,衡量预测与真实之间的差距。回归问题根据数据特征选择:无异常值用 MSE,有异常值用 MAE 或 Huber 损失。分类问题使用交叉熵损失,配合对应的激活函数,梯度计算高效。
激活函数和损失函数的设计直接影响网络的训练效率、收敛速度和最终性能。理解各函数的特性,根据任务类型和网络结构选择合适的组合,是深度学习实践必须掌握的技能。下一章将进入第二部分"神经网络优化",介绍梯度下降算法和自适应优化器。
练习题
设深层网络使用 Sigmoid 激活函数,分析经过 层后梯度衰减程度。如果改用 ReLU,梯度传递有何不同?
参考答案
Sigmoid 导数 ,最大值为 (当 )。反向传播中,每经过一层 Sigmoid,梯度乘以 。设各层激活值恰好处于导数最大点(理想情况),经过 层后梯度保留比例为:
计算不同深度的梯度保留:
层数 梯度保留比例 实际意义 1 25% 可训练 2 6.25% 较慢 5 0.001% 几乎消失 10 % 完全消失 实际情况更糟糕,因为激活值不可能全部处于导数最大点;初始化不当也可能导致激活值进入导数接近 0 的区域;训练过程中激活值分布可能漂移
ReLU 梯度传递分析:
ReLU 导数在正数区域恒为 。反向传播中,激活神经元()的梯度完整传递,不衰减。设各层激活比例为 (即 比例的神经元 ),经过 层后:
- 激活路径的梯度完整保留
- 不激活路径的梯度为 (完全截断)
梯度传递公式:
其中 是一个 矩阵:
- 时,
- 时,
ReLU vs Sigmoid 对比:
特性 Sigmoid ReLU 导数范围 梯度衰减 逐层指数衰减 激活神经元不衰减 深层训练 几乎不可能 可行 问题 梯度消失 神经元死亡 ReLU 的优势:
- 梯度在激活路径完整传递,深层网络前面几层仍能获得有效梯度。
- 稀疏激活特性:不激活神经元梯度为 0,相当于"自动选择"哪些路径传递梯度。
- 深层网络训练变得可行。
ReLU 的注意点:
- 神经元死亡:不激活神经元永远不更新。
- 需要合适的初始化(He 初始化)保证足够的激活比例。
- 激活路径的梯度完整传递,但也可能导致梯度爆炸(权重过大时)。
总结:Sigmoid 梯度逐层指数衰减,深层网络前面几层几乎无法训练。ReLU 激活路径梯度不衰减,使深层网络训练可行。这是 ReLU 成为深度学习主流激活函数的核心原因。
证明当使用 Sigmoid 输出层配合 Binary Cross-Entropy 损失时,梯度 。这个简化有什么意义?
参考答案
梯度推导:
设 Sigmoid 输出 ,Binary Cross-Entropy 损失 。
计算损失对 的梯度:
首先,:
然后,(Sigmoid 导数):
代入:
简化意义:
计算高效:无需显式计算 Sigmoid 导数,直接取预测概率与真实标签的差值。省去复杂的导数计算,提高训练效率。
数值稳定:避免了单独计算 和 可能导致的数值问题(当 接近 0 或 1)。
梯度直观:误差信号 直观表示"预测误差":
- 预测正确():梯度为 0
- 预测偏高():梯度为正,参数向减小预测方向更新
- 预测偏低():梯度为负,参数向增大预测方向更新
避免梯度消失:即使 接近 0 或 1,梯度仍与预测误差成比例,不会消失。这与 MSE + Sigmoid 不同(后者在预测接近真实时梯度消失)。
统一形式:与 Softmax + Cross-Entropy 的梯度形式一致(都是 ),便于理解和实现。
总结:Sigmoid + Binary Cross-Entropy 的梯度简化是深度学习训练效率的关键之一。它使梯度计算简洁高效,同时避免了数值问题和梯度消失。这就是为什么 Cross-Entropy 是分类问题的标准损失函数。
分析 MSE 在分类任务中为何表现不佳。设使用 Sigmoid 输出层,推导 MSE 损失的梯度,并说明其缺陷。
参考答案
MSE 在分类中的缺陷:
梯度消失问题:
当 且预测接近正确():
- 梯度
同样,当 且预测接近正确():
- 梯度
这意味着当预测接近正确时,梯度消失,参数几乎不更新。但此时损失并未达到最小(预测仍有改进空间),模型无法继续优化。
惩罚不合理:
MSE 假设预测值和真实值都是连续数值,对差值平方惩罚。但分类问题的真实值是类别标签(0 或 1),MSE 的平方惩罚在语义上不合适。
输出范围不约束:
MSE 不约束输出范围,理论上优化结果可能使 超出 (虽然 Sigmoid 自然约束,但 MSE 的目标函数不尊重概率语义)。
收敛缓慢:
由于梯度消失问题,MSE 在分类任务中收敛比 Cross-Entropy 慢。实验表明,Cross-Entropy 在相同迭代次数下通常达到更好的精度。
与 Cross-Entropy 对比:Cross-Entropy 的梯度 :
- 与预测误差成比例,不随预测接近真实而消失
- 只要预测不完全正确,梯度就有意义
- 收敛更快,效率更高
总结:MSE 在分类任务中的缺陷源于其梯度包含 Sigmoid 导数因子 ,当预测接近真实时该因子趋近于 0,导致梯度消失。Cross-Entropy 通过巧妙设计,梯度恰好消去这个因子,避免梯度消失。这是 Cross-Entropy 成为分类问题标准损失函数的核心原因。