核技巧
长期以来,线性模型一方面因有严谨的理论支撑和快速的求解方法备受青睐,另一方面应用场景又受制于大量问题是非线性的现实困境。人们自然会期望能在不改变算法核心逻辑的前提下,让线性分类器处理非线性数据,1964 年三位苏联数学家曾提出用"隐式映射"绕过高维空间计算,这一思想虽然当时并未引起广泛关注,却埋下了核技巧的种子。
真正让核技巧走向成熟的是弗拉基米尔·瓦普尼克(Vladimir Vapnik)。1992 年,瓦普尼克与同事合作发表了论文《A Training Algorithm for Optimal Margin Classifiers》,首次将核技巧系统地引入支持向量机,原本只能处理线性问题的 SVM,突然拥有了处理复杂非线性模式的能力,同时保持了算法的优雅与高效。后来瓦普尼克在《The Nature of Statistical Learning Theory》一书中进一步阐述了这一思想的深层意义,核技巧由此成为机器学习领域的经典范式。
特征空间升维
回顾上一章学习的 SVM 最大间隔原理,很容易发现一个隐含前提:数据必须是线性可分或近似线性可分的。当数据分布呈现复杂的非线性模式时,"用一个超平面分开正负类数据"这个假设就失效了。如下图所示,找不到任何超平面能够区分出两类数据。
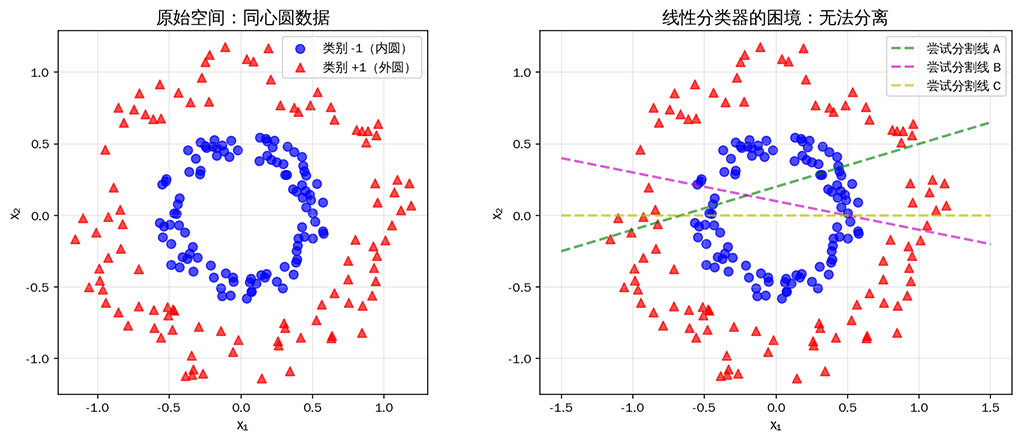
图:同心圆数据分布(左)与线性分类器的困境(右)。无论尝试多少条分割线,都无法将内圆和外圆完全分开
面对这类线性不可分的数据,传统的方法是设计非线性决策边界,但这意味着必须抛弃 SVM 的优雅数学框架。核技巧(Kernel Trick)提供了一种更聪明的解决方案,将数据映射到高维空间,在高维空间中用线性分隔。更妙的是,我们可以隐式地完成这个映射,而不需要显式计算高维特征坐标,从而巧妙地绕开了维度爆炸的计算陷阱。在高维空间中,原本线性不可分的数据可能变得线性可分。这背后的数学原理可以追溯到 1965 年提出的 Cover 定理。
Cover 定理
假设有一个映射函数 ,将原始特征映射到更高维的空间 $$,数据随机映射到足够高维的空间后,数据变得线性可分的概率会显著增加。
用一个生活例子来类比,想象你在桌上撒了一把黑白混杂的芝麻和米粒。在桌面上,芝麻和白米交织在一起,你很难用一根棍子把它们完全分开。但如果你把芝麻和米粒放到一桶水里,芝麻会浮在水面,米粒会沉入水底(这个例子中米粒与芝麻的比重不同就是隐含的高维特征),那用一张纸就能轻松分隔它们,如下图所示:
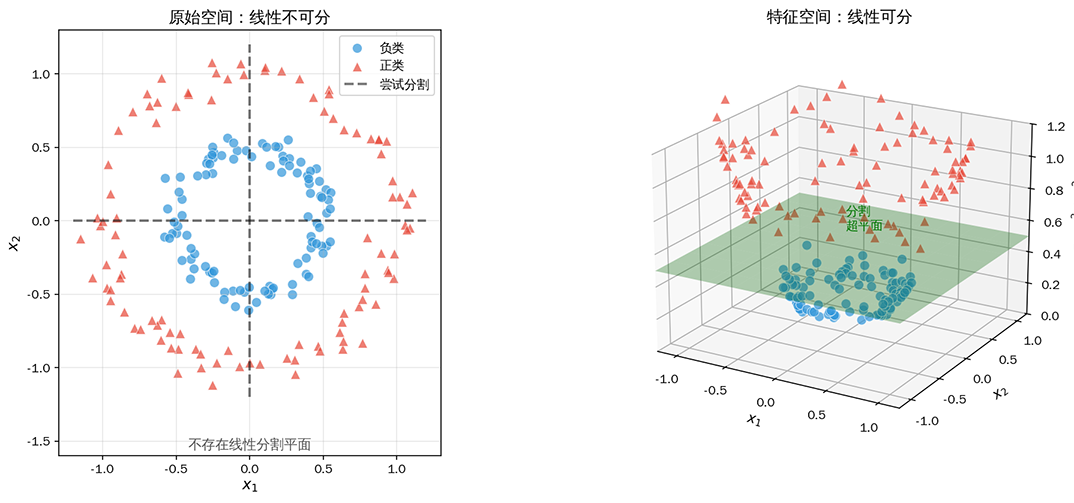
图:低维空间的非线性可分数据(左)通过映射到高维空间后变得线性可分(右)。蓝色圆点为负类,红色三角为正类,绿色平面为高维空间中的分割超平面
再举一个具体的数值例子来展示应用 Cover 定理升维的效果。考虑一维数据 ,其中负样本为 、正样本为 ,如下图所示。在一维空间中,无论选择哪个分割点,都会错误分类部分样本,因为正负样本交错分布,不存在"一刀切"的解。但如果将数据映射到二维空间 ,情况就完全改变了。观察右图,所有负样本(蓝色圆点)落在抛物线的底部区域,而正样本(红色三角点)分布在两侧高处。一条水平分割线 就能完美分开两类样本。这再次说明原始空间中看似复杂的非线性模式,在高维空间中可能只是简单的线性模式,只要我们换了一个更"宽敞"的坐标系来观察它。
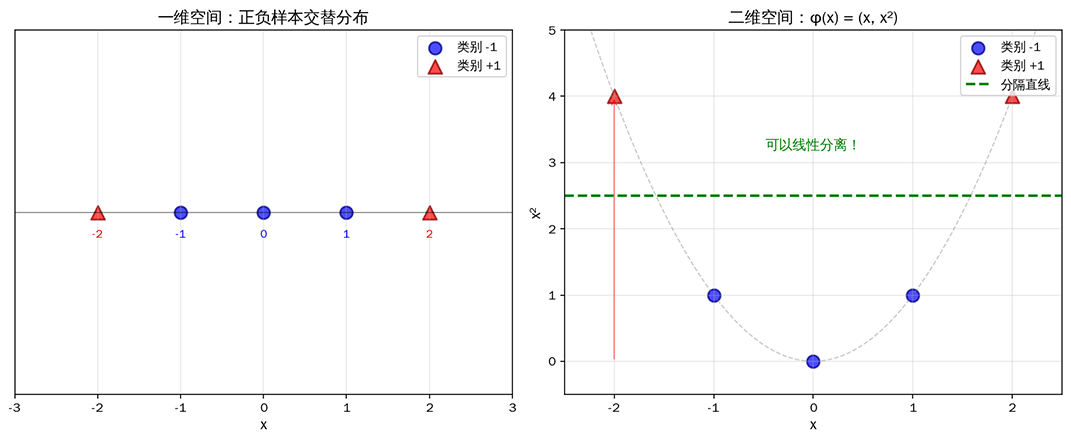
图:一维空间中正负样本交替分布(左),映射到二维空间后可用直线分离(右)
升维策略虽然效果显著,却并非没有代价,在 SVM 应用实践中面临以下两个严峻挑战:
存储成本:对于多项式映射,特征维度会急剧增长。原始特征有 维,映射到所有次数不超过 的多项式组合后,特征维度变为 。譬如,当 、 时,新维度高达 。如果是 RBF 核,对应的特征空间甚至是无穷维,理论上根本无法存储。
计算成本:即使维度存储成本可以接受,SVM 的对偶问题目标函数中,样本以成对内积形式出现( 形式,推导见 SVM 的拉格朗日对偶变换),升维映射后变为 ,需要先执行映射操作,再计算维度膨胀后的内积。两个步骤叠加,时间复杂度难以接受。
这正是核技巧登场的时机。核技巧的创新不在于升维本身,而是巧妙地解决了上述两个难题,不需要显式计算 ,只需要计算内积 ,而这可以通过核函数直接完成,完全绕过映射步骤。
隐式内积计算
理解了升维的价值和代价后,核技巧(Kernel Trick)可以概括为一句话:不显式构造高维映射 ,而是直接计算出高维空间中样本的内积 的等效结果。这意味着无论映射后的空间是千维万维还是无穷维,因为不会构造出 的具体形式,就不需要存储高维向量。其次,计算成本也大幅降低了,因为不再需要先映射再内积的两步操作,而是从核函数中直接得到与内积计算等效的结果。
这一切的关键是引入了核函数(Kernel Function),它的值等于两个样本在特征空间中映射后的内积。不妨将核函数想象成一个翻译器,它能直接告诉你两个样本在高维空间中有多相似,却不需要你真正走到那个高维空间去丈量。就像你能通过口音来判断两个人是否来自同一个地区,而不需要通过户籍系统精确查询他们的具体住址。核函数的理论基础来自 1909 年的 Mercer 定理。
Mercer 定理
一个函数 能成为有效核函数,当且仅当对于任意数据集 ,由 定义的核矩阵 是半正定的。
要理解这句话,需先解释两个相关概念,一个是核矩阵(Kernel Matrix),也称为 Gram 矩阵,在 SVM 实践中我们已经当作内积计算的缓存使用过它。核矩阵是将核函数应用到数据集中所有样本对上所形成的矩阵。假设有 个样本 ,核矩阵 是一个 的对称矩阵,其第 行第 列的元素定义为 。根据向量内积的几何意义,核矩阵存储了所有样本在特征空间中的两两相似度,每个元素 告诉我们样本 和 在高维空间中有多相似。
另一个概念是半正定矩阵(Positive Semi-Definite Matrix),它的数学定义是对于任意向量 ,半正定矩阵 满足 。半正定矩阵的含义可以理解为保证了核函数对应于某个特征空间中的有效内积运算。如果一个核矩阵是半正定的,那么对于任意系数向量,核矩阵的二次型恒非负,这保证了核函数确实对应于某个特征空间中的内积运算,在几何上意味着空间不会被扭曲成奇怪的形状。
现在回到 SVM 的对偶问题,要注意到在对偶问题中无论是优化目标函数还是决策函数,样本特征 从未单独出现过,永远是以内积 的形式成对出现的。这就意味着我们不需要知道映射后样本特征变成了什么样子,只要知道映射后两个样本的相似度就够了。
因此,核技巧只是将 替换为 ,SVM 便有了处理非线性问题的能力,这个替换看似简单,却完整保留了 SVM 算法的核心逻辑(最大化间隔),只是把"原始空间的相似度"换成了"高维空间的相似度"。
常见核函数
选择合适的核函数,本质上是在模型复杂度与计算效率之间寻找平衡。三种最常用的核函数:线性核、多项式核和 RBF 核,恰好代表了从简单到复杂的连续谱系,理解它们的差异有助于在实际问题中做出恰当选择。
线性核
线性核是核函数家族中最简单的成员,它直接计算原始特征空间的内积 。严格来说,线性核甚至不涉及升维,它完全保留了原始特征空间的结构。这种不做任何变换的特性恰恰是其最大优势:计算成本最低,理论可解释性最强。
线性核听起来似乎什么都没有改变,那它起什么用?第一是线性核将线性可分数据的场景统一到核技巧的框架中来,如果为了升维而升维,强行使用复杂核函数只会增加调参负担和过拟合风险。还有一种情况是特征维度极高而样本数量相对较少时,线性核往往反而是好的选择。文本分类就是典型例子,用词袋模型表示的文档,特征维度轻松达到数万甚至数十万(对应词汇表大小),而样本可能只有几千条。高维空间本身就提供了充足的分离自由度,此时非线性核的升维收益很有限,反而会拖慢训练速度。
多项式核
如果说线性核是零升维,多项式核则走向了另一个极端,它显式地构造出有限维的高阶特征空间 ,其中 是多项式次数, 是常数偏移项(通常设为 0 或 1)。这个公式展开后,对应的特征空间包含了原始特征的所有 次及以下的组合。譬如,对于二维特征 ,二次多项式核 对应的显式映射为:
注意这里的系数设计,交叉项 带有 系数,这是为了保证展开后各项权重一致。原始特征维度为 、多项式次数为 时,升维后的特征数量为 。当 、 时,维度从 100 膨胀到 176,851,存储成本已经相当可观。
多项式核的价值在于显式建模特征之间的交互关系。如果领域先验知识告诉我们,某些特征的组合对预测目标至关重要(譬如"年龄"与"收入"的乘积对消费能力的预测),多项式核提供了一种直接引入这类交互项的机制。与 RBF 核的黑盒非线性不同,多项式核的映射是透明可解释的,我们知道模型看到了哪些阶次的特征组合。
不过,多项式核在实践中使用率相对较低,原因是它并没有解决升维带来的存储成本与计算成本的问题,而且在大多数非线性问题上,RBF 核的表现往往不逊色于多项式核,甚至更优。
RBF 核
RBF 核(Radial Basis Function,径向基函数),又称高斯核,是核 SVM 中最受欢迎的选择,它的核函数表示为:
这里的 是控制高斯分布宽窄的参数。与多项式核的有限维特征空间不同,RBF 核对应的特征空间是无穷维的。理论上,它能表示原始空间中任意复杂的非线性模式,这使其成为一种"万能"的非线性工具。
理解 RBF 核的直观方式是观察其随距离衰减的特性。当两个样本在原始空间中的欧氏距离 很大时,核函数值指数级趋近于 0,意味着它们在高维特征空间中几乎正交(不相似);当距离为 0(即两个样本重合)时,核函数值为 1(最大相似度)。这种局部敏感的特性使得 RBF 核 SVM 的决策边界能够灵活地贴合数据的局部分布,每个支持向量就像一个影响源,在其周围形成一个高斯形状的"势力范围",所有影响源的叠加构成了最终的决策曲面。
参数 控制着每个支持向量的势力半径。 值较大时,高斯分布变窄,每个支持向量的影响范围局限在邻近区域,模型倾向于为每个局部数据簇量身定制决策边界,可能导致过拟合。 值较小时,高斯分布变宽,单个支持向量的影响范围扩大,决策边界变得更平滑,模型复杂度降低,可能欠拟合。这种"半径 - 复杂度"的对应关系是 RBF 核调参的直觉。
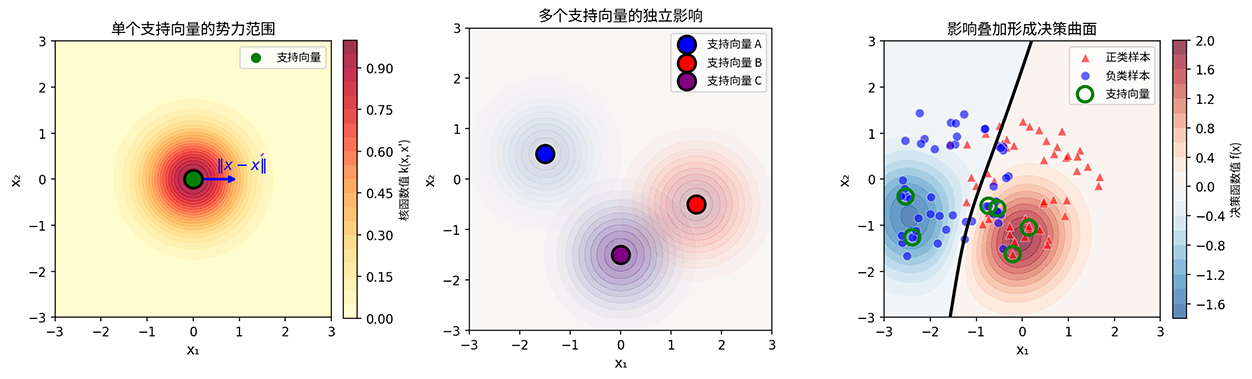
图:RBF 核支持向量的"势力范围"概念示意
上图展示了 RBF 核 SVM 决策机制的本质。
- 左图呈现单个支持向量周围的核函数值分布,这是一个以支持向量为中心的高斯曲面,距离越远函数值衰减越快,正是"势力范围"的数学表达。
- 中图展示了多个支持向量同时存在时,各自独立产生的高斯影响场在空间中的分布。
- 右图则揭示最终决策曲面的形成机制:每个支持向量的影响按其类别标签(正类为正权重、负类为负权重)进行加权,然后在空间中叠加,当叠加结果为零时即形成决策边界(黑色曲线)。这种局部敏感的特性使 RBF 核能够灵活地贴合任意复杂的局部分布,每个支持向量只在邻近区域发挥影响,而整体的决策曲面则是所有支持向量影响的加权总和。
三种核函数的特征与适用场景总结如下表所示:
| 核函数 | 参数 | 特征空间维度 | 适用场景 |
|---|---|---|---|
| 线性核 | 无 | 原始维度 | 线性可分、高维稀疏数据 |
| 多项式核 | (有限维) | 特征交互明确的场景 | |
| RBF 核 | 无穷维 | 通用非线性问题 |
三种核函数的选择可以遵循一条渐进式的决策路径。面对新问题,首先观察数据特性。如果特征维度与样本数量相当或更高(如文本、基因数据),优先尝试线性核。高维稀疏数据本身已提供充足的分离自由度,非线性核的升维收益有限。如果数据明显非线性可分且特征维度不高,RBF 核是更安全的默认选择,它凭借无穷维特征空间的表达能力,能够适应各种复杂的边界形状。多项式核则适合那些对特征交互有明确建模需求的场景,或者作为 RBF 核效果不佳时的备选方案。
值得强调的是,核函数并非越复杂越好。线性核虽然简单,但在许多真实数据集上表现优异,且具备不可替代的可解释性优势。RBF 核虽然理论上能拟合任意模式,却也更易过拟合,需要配合交叉验证仔细调参。实践中一个常见的误区是看到线性核准确率只有 70% 就急于尝试 RBF 核,却忽略了那 30% 的错误可能源于数据本身的噪声或标注错误,而非模型表达能力不足。在机器学习的世界里,"恰到好处"的复杂度往往胜过"过度强大"的模型。
核 SVM 实践
前面我们讨论了核技巧的理论基础,接下来要将这些理论转化为可运行的代码。以下代码支持线性核、多项式核和 RBF 核三种常用核函数,采用对偶问题的梯度上升求解方法,不妨与前面软间隔 SVM 的实践进行对比理解。核 SVM 的实现思路主要分为四个步骤:
第一步:核矩阵计算:与软间隔 SVM 的线性核不同,核 SVM 需要根据不同的核函数计算核矩阵 。对于线性核,,直接使用矩阵乘法计算;对于多项式核,,先计算内积再进行多项式变换;对于 RBF 核,,利用距离公式 进行向量化计算,避免显式循环。核矩阵是对称矩阵,存储了所有样本对在特征空间中的相似度。
第二步:迭代更新拉格朗日乘子 :核 SVM 的对偶问题形式与软间隔 SVM 相同,目标函数为 ,唯一的区别是将内积 替换为核函数 。采用梯度上升法优化,对于每个 ,其梯度为 。每次迭代更新后将 投影到约束区间 内,并对所有 进行均值修正以满足等式约束 。
第三步:识别支持向量与计算偏移量 :训练完成后,筛选支持向量(满足 的样本),其中自由支持向量满足 。与线性 SVM 不同,核 SVM 不显式计算法向量 ,而是直接使用支持向量及其对应的标签和拉格朗日乘子来表示模型。偏移量 通过支持向量的平均偏差计算:。
第四步:构建决策函数:核 SVM 的决策函数为 。预测时,新样本与所有支持向量计算核函数值,加权求和后加上偏移量得到决策值。预测时根据决策值的符号判断类别 。这种形式完全绕过了高维特征空间的显式计算,只需在原始空间计算核函数即可完成预测。
import numpy as np
class KernelSVM:
"""
核SVM实现
支持线性核、多项式核、RBF核
"""
def __init__(self, kernel='rbf', C=1.0, gamma=1.0, degree=3, coef0=1):
self.kernel = kernel
self.C = C
self.gamma = gamma
self.degree = degree
self.coef0 = coef0 # 多项式核的常数项
self.alpha = None
self.b = None
self.X_train = None
self.y_train = None
self.support_vectors_ = None
self.support_vector_labels_ = None
self.alpha_sv = None
def _kernel(self, X1, X2):
"""计算核矩阵"""
if self.kernel == 'linear':
return X1 @ X2.T
elif self.kernel == 'poly':
return (X1 @ X2.T + self.coef0) ** self.degree
elif self.kernel == 'rbf':
# ||x - x'||^2 = ||x||^2 + ||x'||^2 - 2*x^T*x'
X1_norm = np.sum(X1 ** 2, axis=1).reshape(-1, 1)
X2_norm = np.sum(X2 ** 2, axis=1).reshape(1, -1)
distances = X1_norm + X2_norm - 2 * X1 @ X2.T
return np.exp(-self.gamma * distances)
else:
raise ValueError(f"未知核函数: {self.kernel}")
def fit(self, X, y, lr=0.01, n_iterations=500):
"""训练模型(简化版SMO思想)"""
n_samples = X.shape[0]
self.X_train = X
self.y_train = y
# 计算核矩阵
K = self._kernel(X, X)
# 初始化
self.alpha = np.zeros(n_samples)
# 梯度上升优化
for _ in range(n_iterations):
for i in range(n_samples):
# 梯度
gradient = 1 - y[i] * np.sum(self.alpha * y * K[:, i])
self.alpha[i] += lr * gradient
self.alpha[i] = np.clip(self.alpha[i], 0, self.C)
# 约束修正:满足等式约束 sum(alpha * y) = 0
# 减去均值偏差后,需再次投影到边界约束 [0, C]
self.alpha = self.alpha - np.mean(self.alpha * y) * y
self.alpha = np.clip(self.alpha, 0, self.C)
# 注意:投影后等式约束可能不再精确满足,但迭代过程中误差会累积抵消
# 支持向量
sv_mask = self.alpha > 1e-5
self.support_vectors_ = X[sv_mask]
self.support_vector_labels_ = y[sv_mask]
self.alpha_sv = self.alpha[sv_mask]
# 计算b
if len(self.support_vectors_) > 0:
K_sv = self._kernel(self.support_vectors_, self.support_vectors_)
margins = np.sum(self.alpha_sv * self.support_vector_labels_ * K_sv, axis=1)
self.b = np.mean(self.support_vector_labels_ - margins)
else:
self.b = 0
return self
def decision_function(self, X):
"""决策函数"""
K = self._kernel(X, self.support_vectors_)
return K @ (self.alpha_sv * self.support_vector_labels_) + self.b
def predict(self, X):
"""预测类别"""
return np.sign(self.decision_function(X)).astype(int)
def score(self, X, y):
"""计算准确率"""
y_pred = self.predict(X)
return np.mean(y_pred == y)
def make_circles(n_samples=200, noise=0.1, factor=0.5):
"""生成同心圆数据"""
n = n_samples // 2
# 内圆
theta_inner = np.random.uniform(0, 2*np.pi, n)
r_inner = factor * np.random.uniform(0.8, 1.2, n)
X_inner = np.column_stack([r_inner * np.cos(theta_inner), r_inner * np.sin(theta_inner)])
# 外圆
theta_outer = np.random.uniform(0, 2*np.pi, n)
r_outer = np.random.uniform(0.8, 1.2, n)
X_outer = np.column_stack([r_outer * np.cos(theta_outer), r_outer * np.sin(theta_outer)])
X = np.vstack([X_inner, X_outer])
y = np.hstack([-np.ones(n), np.ones(n)])
# 添加噪声
X += np.random.randn(*X.shape) * noise
return X, y
X, y = make_circles(n_samples=200, noise=0.1)
# 对比不同核函数
print("=== 不同核函数对比(同心圆数据)===\n")
kernels = [
('linear', {}),
('poly', {'degree': 2}),
('rbf', {'gamma': 1.0})
]
for kernel_name, params in kernels:
svm = KernelSVM(kernel=kernel_name, C=1.0, **params)
svm.fit(X, y, lr=0.01, n_iterations=300)
acc = svm.score(X, y)
print(f"{kernel_name:8}核: 准确率 = {acc:.3f}, 支持向量数 = {len(svm.support_vectors_)}")
应用场景:信用风险预测
SVM 在金融科技领域有着广泛应用,尤其在信用风险评估场景。下面我们将使用德国信用数据集(German Credit Data),演示 RBF 核 SVM 如何预测客户的信贷违约风险。该问题具有明显的非线性特征,客户的还款能力与收入、年龄、负债比例等多个因素存在复杂的交互关系,难以用简单的线性规则来划分高风险与低风险客户。
该数据集包含 1000 个信贷申请记录,每个样本有 20 个特征(经预处理后选取 7 个关键数值特征),如贷款金额、贷款期限、分期付款占可支配收入比率、当前居住年限、年龄、现有信用卡数量、现有信贷数量。这是一个典型的非线性二分类问题:客户的违约风险与其多维财务特征之间不存在简单的线性边界。
import matplotlib.pyplot as plt
import numpy as np
from shared.svm.kernel_svm import KernelSVM
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 模拟德国信用数据集的关键特征
n_samples = 400
# 生成特征数据
# 特征1: 分期付款占可支配收入比率 (0-100)
installment_ratio = np.random.uniform(0, 100, n_samples)
# 特征2: 贷款金额 (标准化到0-100)
loan_amount = np.random.uniform(0, 100, n_samples)
# 特征3: 当前居住年限 (0-30)
residence_years = np.random.uniform(0, 30, n_samples)
# 特征4: 年龄 (18-75)
age = np.random.uniform(18, 75, n_samples)
# 特征5: 现有信用卡数量
credit_cards = np.random.poisson(2, n_samples)
# 特征6: 现有信贷数量
existing_credits = np.random.poisson(1, n_samples)
# 特征7: 贷款期限 (月)
duration = np.random.uniform(6, 72, n_samples)
# 构建特征矩阵
X_full = np.column_stack([installment_ratio, loan_amount, residence_years, age, credit_cards, existing_credits, duration])
# 生成标签:非线性决策边界
# 高风险客户:分期付款比例高、贷款金额大、居住年限短、年龄小、信用卡多、现有信贷多、贷款期限长
risk_score = (0.5 * installment_ratio + 0.3 * loan_amount - 0.2 * residence_years - 0.15 * age + 5 * credit_cards + 3 * existing_credits + 0.1 * duration)
# 添加非线性交互项和噪声
risk_score += 0.01 * installment_ratio * loan_amount / 10 # 交互项
risk_score += np.random.randn(n_samples) * 5 # 噪声
y = np.where(risk_score > np.median(risk_score), -1, 1) # -1=高风险, 1=低风险
# 标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_full)
# 使用PCA降维到2维用于可视化
pca = PCA(n_components=2)
X = pca.fit_transform(X_scaled)
# 训练不同核函数的SVM
kernels = [
('linear', {}),
('poly', {'degree': 2}),
('rbf', {'gamma': 0.5})
]
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for idx, (kernel_name, params) in enumerate(kernels):
svm = KernelSVM(kernel=kernel_name, C=1.0, **params)
svm.fit(X, y, lr=0.01, n_iterations=300)
acc = svm.score(X, y)
print(f"{kernel_name:8}核: 准确率 = {acc:.3f}, 支持向量数 = {len(svm.support_vectors_)}")
ax = axes[idx]
# 创建网格用于绘制决策边界
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
grid = np.c_[xx.ravel(), yy.ravel()]
Z = svm.decision_function(grid).reshape(xx.shape)
# 绘制决策区域
ax.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap='Blues', alpha=0.5)
ax.contourf(xx, yy, Z, levels=np.linspace(0, Z.max(), 7), cmap='Reds', alpha=0.5)
ax.contour(xx, yy, Z, levels=[0], linewidths=2, colors='black')
# 绘制数据点
ax.scatter(X[y == -1, 0], X[y == -1, 1], c='blue', marker='o', s=50, label='高风险客户', alpha=0.7, edgecolors='k', linewidths=0.3)
ax.scatter(X[y == 1, 0], X[y == 1, 1], c='red', marker='^', s=50, label='低风险客户', alpha=0.7, edgecolors='k', linewidths=0.3)
# 绘制支持向量
ax.scatter(svm.support_vectors_[:, 0], svm.support_vectors_[:, 1], s=120, facecolors='none', edgecolors='green', linewidths=2, label=f'支持向量({len(svm.support_vectors_)}个)')
ax.set_xlabel('主成分 1', fontsize=11)
ax.set_ylabel('主成分 2', fontsize=11)
ax.set_title(f'{kernel_name.upper()} 核 (准确率: {acc:.3f})', fontsize=12)
ax.legend(loc='upper right', fontsize=9)
ax.grid(True, alpha=0.3)
plt.suptitle('信用风险预测:不同核函数的决策边界对比', fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
plt.close()
上图展示了核技巧在金融风控领域的实际应用效果:
- 左图 线性核:假设高风险与低风险客户之间存在线性边界。这在现实中常常不成立,因为客户的还款能力受多重因素交互影响。线性核的准确率通常较低,无法捕捉复杂的财务行为模式。
- 中图 多项式核:通过二次映射捕捉特征间的交互关系(如"高负债比例 + 年轻年龄"的组合风险)。这更符合现实逻辑:金融风险常常不是单一因素决定的,而是多个因素组合的结果。多项式核相比线性核有明显提升。
- 右图 RBF 核:展现了核技巧的真正威力。决策边界呈现为复杂的非线性曲面,能够灵活适应数据的局部分布。RBF 核通过无穷维特征空间的映射,捕捉了信用风险中难以显式建模的复杂模式,一般能获得最高的分类准确率。
支持向量(绿色空心圆圈)的分布揭示了模型的关注点,它们主要分布在决策边界附近,代表那些财务特征"模糊"的边界客户。在复杂的特征空间中,少数关键样本就能定义出清晰的决策边界,帮助银行在放贷决策中识别高风险申请。
本章小结
在核技巧下,SVM 的最大间隔原理、凸优化性质、全局最优解保证等优雅的数学特性全部得以保留,仅仅通过替换内积运算,线性方法就获得了处理任意非线性模式的能力。核 SVM 展示了机器学习方法的"外观"可以保持不变,只需要换掉内部的"度量标准"来获得新的能力,无论是本章介绍的核 SVM,还是我们在线性模型中接触过的 GLM 框架都是这种思想的体现。
练习题
为什么核技巧不需要显式计算高维映射 ?请从计算复杂度的角度分析,并说明核函数如何"隐式"地完成这一过程。
参考答案
核技巧的洞察在于:SVM 的对偶问题和决策函数中,我们只需要计算样本之间的内积 ,而不需要知道样本在高维空间的具体坐标 。
从计算复杂度角度分析:
- 显式映射:需要先计算 (维度可能高达数十万甚至无穷),再计算内积,复杂度为 ,其中 是高维特征空间的维度
- 核函数:直接计算 ,复杂度为 ,其中 是原始特征维度
譬如,对于 RBF 核 ,其对应的特征空间是无穷维的,理论上不可能显式计算 。但核函数只需计算原始空间的欧氏距离( 复杂度),就能得到无穷维空间中的内积结果。这就是核技巧"隐式升维"的精髓:只计算结果,不关心过程。
设 ,多项式核函数为 。请推导该核函数对应的显式映射 ,并验证 。
参考答案
首先展开核函数:
观察这个表达式,可以将其写成两个向量的内积形式:
验证:
这与核函数的展开完全一致,验证成功。
这个例子说明:多项式核 将二维特征映射到三维特征空间,包含了所有二次特征组合(, 和交叉项 )。系数 的引入是为了保证各项权重一致,避免交叉项被低估。
使用本章实现的
KernelSVM类,在以下数据集上对比不同核函数的表现:- 生成两个月牙形数据(
make_moons) - 训练线性核、多项式核()和 RBF 核()的 SVM
- 绘制三种核函数的决策边界,分析哪种核最适合该数据集
- 生成两个月牙形数据(
参考答案
import numpy as np
import matplotlib.pyplot as plt
from shared.svm.kernel_svm import KernelSVM
def make_moons(n_samples=200, noise=0.15):
"""生成月牙形数据"""
n = n_samples // 2
# 上月牙
theta_upper = np.random.uniform(0, np.pi, n)
X_upper = np.column_stack([np.cos(theta_upper), np.sin(theta_upper)])
# 下月牙(平移)
theta_lower = np.random.uniform(0, np.pi, n)
X_lower = np.column_stack([1 - np.cos(theta_lower), -np.sin(theta_lower) - 0.5])
X = np.vstack([X_upper, X_lower])
y = np.hstack([np.ones(n), -np.ones(n)])
# 添加噪声
X += np.random.randn(*X.shape) * noise
return X, y
# 生成数据
X, y = make_moons(n_samples=200, noise=0.15)
# 训练三种核函数
kernels = [
('linear', {}),
('poly', {'degree': 3}),
('rbf', {'gamma': 0.5})
]
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for idx, (kernel_name, params) in enumerate(kernels):
svm = KernelSVM(kernel=kernel_name, C=1.0, **params)
svm.fit(X, y, lr=0.01, n_iterations=500)
acc = svm.score(X, y)
ax = axes[idx]
# 绘制决策边界
xx, yy = np.meshgrid(np.linspace(-1.5, 2.5, 100), np.linspace(-1.5, 1.5, 100))
grid = np.c_[xx.ravel(), yy.ravel()]
Z = svm.decision_function(grid).reshape(xx.shape)
ax.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap='Blues', alpha=0.5)
ax.contourf(xx, yy, Z, levels=np.linspace(0, Z.max(), 7), cmap='Reds', alpha=0.5)
ax.contour(xx, yy, Z, levels=[0], linewidths=2, colors='black')
ax.scatter(X[y == -1, 0], X[y == -1, 1], c='blue', marker='o', alpha=0.7)
ax.scatter(X[y == 1, 0], X[y == 1, 1], c='red', marker='^', alpha=0.7)
ax.set_xlabel('x₁')
ax.set_ylabel('x₂')
ax.set_title(f'{kernel_name}核 (准确率: {acc:.3f})')
ax.set_aspect('equal')
plt.tight_layout()
plt.show()
plt.close()