上一章我们学习了单变量函数的导数和微分,建立了变化率的基本概念。然而,机器学习中的大多数问题涉及多个变量,譬如神经网络的参数可能有数百万甚至数十亿个,损失函数是这些参数的多元函数。本章将把导数概念推广到多元函数,介绍偏导数、梯度、链式法则、方向导数和海森矩阵等核心概念,为理解机器学习优化算法奠定理论基础。
多元函数 (Multivariate Function)是单变量函数的自然推广。一个 n n n f f f n n n ( x 1 , x 2 , … , x n ) (x_1, x_2, \ldots, x_n) ( x 1 , x 2 , … , x n ) L ( θ 1 , θ 2 , … , θ n ) L(\theta_1, \theta_2, \ldots, \theta_n) L ( θ 1 , θ 2 , … , θ n ) ( x 1 , x 2 , … , x n ) (x_1, x_2, \ldots, x_n) ( x 1 , x 2 , … , x n ) f ( x 1 , x 2 , … , x n ) f(x_1, x_2, \ldots, x_n) f ( x 1 , x 2 , … , x n )
当我们处理多元函数时,首先想到的是用固定变量的思维将问题简化,去思考如果只让其中一个变量变化,而保持其他变量不变,函数值会如何变化?这正是偏导数 (Partial Derivative)解决问题的思路。设 z = f ( x , y ) z = f(x, y) z = f ( x , y ) f f f ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) x x x y y y x x x Δ x \Delta x Δ x
∂ f ∂ x = lim Δ x → 0 f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 ) Δ x \frac{\partial f}{\partial x} = \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x, y_0) - f(x_0, y_0)}{\Delta x} ∂ x ∂ f = Δ x → 0 lim Δ x f ( x 0 + Δ x , y 0 ) − f ( x 0 , y 0 ) 类似地,关于 y y y
∂ f ∂ y = lim Δ y → 0 f ( x 0 , y 0 + Δ y ) − f ( x 0 , y 0 ) Δ y \frac{\partial f}{\partial y} = \lim_{\Delta y \to 0} \frac{f(x_0, y_0 + \Delta y) - f(x_0, y_0)}{\Delta y} ∂ y ∂ f = Δ y → 0 lim Δ y f ( x 0 , y 0 + Δ y ) − f ( x 0 , y 0 ) 求 f ( x , y ) f(x, y) f ( x , y ) x x x y y y x x x 导数运算法则 依然适用。设 f ( x , y ) = x 2 y + 3 x y 2 f(x, y) = x^2 y + 3xy^2 f ( x , y ) = x 2 y + 3 x y 2 ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f y y y ∂ f ∂ x = 2 x y + 3 y 2 \frac{\partial f}{\partial x} = 2xy + 3y^2 ∂ x ∂ f = 2 x y + 3 y 2 ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f x x x ∂ f ∂ y = x 2 + 6 x y \frac{\partial f}{\partial y} = x^2 + 6xy ∂ y ∂ f = x 2 + 6 x y
导数在几何上被视为切线的斜率,偏导数有同样直观的几何解释。对于二元函数 z = f ( x , y ) z = f(x, y) z = f ( x , y ) ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f x x x ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f y y y ∂ f ∂ x ( x 0 , y 0 ) \frac{\partial f}{\partial x}(x_0, y_0) ∂ x ∂ f ( x 0 , y 0 ) y = y 0 y = y_0 y = y 0 ( x 0 , y 0 , f ( x 0 , y 0 ) ) (x_0, y_0, f(x_0, y_0)) ( x 0 , y 0 , f ( x 0 , y 0 )) y y y x x x
那如果我们不想局限于固定坐标轴,想知道沿任意方向的变化率呢?这就需要方向导数 (Directional Derivative):设 f ( x , y ) f(x, y) f ( x , y ) u = ( u 1 , u 2 ) \mathbf{u} = (u_1, u_2) u = ( u 1 , u 2 ) ∥ u ∥ = 1 \|\mathbf{u}\| = 1 ∥ u ∥ = 1 f f f ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) u \mathbf{u} u
D u f ( x 0 , y 0 ) = lim h → 0 f ( x 0 + h u 1 , y 0 + h u 2 ) − f ( x 0 , y 0 ) h D_{\mathbf{u}} f(x_0, y_0) = \lim_{h \to 0} \frac{f(x_0 + h u_1, y_0 + h u_2) - f(x_0, y_0)}{h} D u f ( x 0 , y 0 ) = h → 0 lim h f ( x 0 + h u 1 , y 0 + h u 2 ) − f ( x 0 , y 0 ) 几何直观上,方向导数表示从点 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) u \mathbf{u} u h h h
偏导数告诉我们函数沿每个坐标轴方向的变化率。如果把所有坐标方向的偏导数信息组合起来,就得到一个向量,称为梯度 (Gradient):设 f ( x 1 , x 2 , … , x n ) f(x_1, x_2, \ldots, x_n) f ( x 1 , x 2 , … , x n )
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , … , ∂ f ∂ x n ) \nabla f = \left(\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \ldots, \frac{\partial f}{\partial x_n}\right) ∇ f = ( ∂ x 1 ∂ f , ∂ x 2 ∂ f , … , ∂ x n ∂ f ) 其中 ∇ \nabla ∇ 梯度算子 (Gradient Operator)。有了梯度后,我们可以从另一个角度来观察方向导数 —— 方向导数是梯度与方向向量的内积:
D u f = ∇ f ⋅ u D_{\mathbf{u}} f = \nabla f \cdot \mathbf{u} D u f = ∇ f ⋅ u 这个公式(在学习链式法则 后可以证明它与前面的定义是等价的)揭示了梯度一个极其重要的几何性质:梯度指向函数值增长最快的方向 。回想一下 内积的定义与几何性质 ,设 θ \theta θ ∇ f \nabla f ∇ f u \mathbf{u} u D u f = ∥ ∇ f ∥ ∥ u ∥ cos θ D_{\mathbf{u}} f = \|\nabla f\| \|\mathbf{u}\| \cos\theta D u f = ∥∇ f ∥∥ u ∥ cos θ ∥ u ∥ = 1 \|\mathbf{u}\| = 1 ∥ u ∥ = 1 D u f = ∥ ∇ f ∥ cos θ D_{\mathbf{u}} f = \|\nabla f\| \cos\theta D u f = ∥∇ f ∥ cos θ cos θ \cos\theta cos θ θ = 0 \theta = 0 θ = 0 u \mathbf{u} u ∇ f \nabla f ∇ f 同向 时,方向导数达到最大值 ∥ ∇ f ∥ \|\nabla f\| ∥∇ f ∥
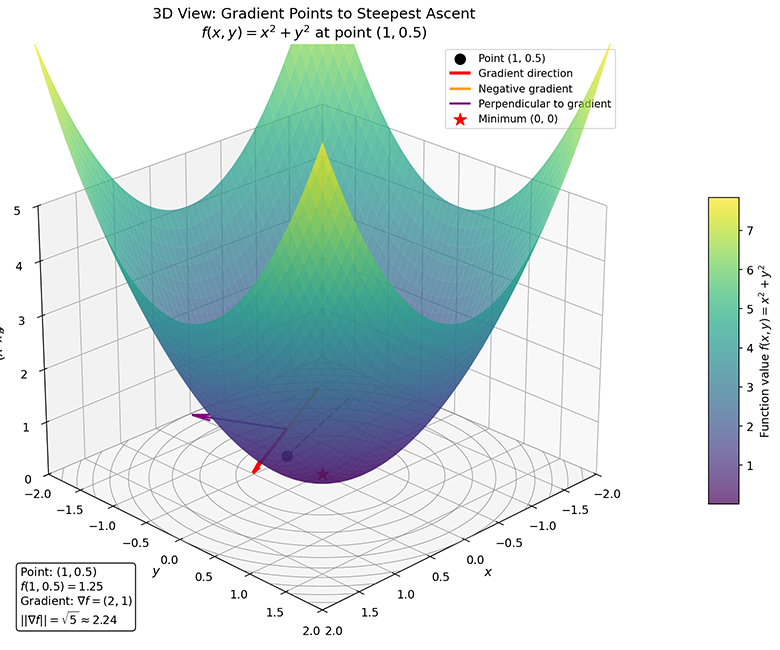
举个具体例子,考虑函数 f ( x , y ) = x 2 + y 2 f(x, y) = x^2 + y^2 f ( x , y ) = x 2 + y 2 ( 1 , 0.5 ) (1, 0.5) ( 1 , 0.5 ) ∇ f = ( 2 x , 2 y ) = ( 2 , 1 ) \nabla f = (2x, 2y) = (2, 1) ∇ f = ( 2 x , 2 y ) = ( 2 , 1 ) ∣ ∣ ∇ f ∣ ∣ = 2 2 + 1 2 = 5 ≈ 2.24 ||\nabla f|| = \sqrt{2^2 + 1^2} = \sqrt{5} \approx 2.24 ∣∣∇ f ∣∣ = 2 2 + 1 2 = 5 ≈ 2.24
图:梯度示例
计算表明,如果沿梯度方向 ( 2 , 1 ) (2, 1) ( 2 , 1 ) ( − 2 , − 1 ) (-2, -1) ( − 2 , − 1 ) ( 1 , − 2 ) (1, -2) ( 1 , − 2 )
梯度这个几何性质对我们后面的学习非常重要,在机器学习的场景里,优化目标通常是最小化损失函数 。设损失函数为 L ( θ ) L(\theta) L ( θ ) θ = ( θ 1 , θ 2 , … , θ n ) \theta = (\theta_1, \theta_2, \ldots, \theta_n) θ = ( θ 1 , θ 2 , … , θ n )
θ t + 1 = θ t − η ∇ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla L(\theta_t) θ t + 1 = θ t − η ∇ L ( θ t ) 这里 η \eta η ∇ L ( θ t ) \nabla L(\theta_t) ∇ L ( θ t )
前面介绍偏导数和梯度时,我们跳过了对梯度与方向向量间内积关系的解释,这是因为过程中要使用到路径复合函数(具体推导见 练习题第 1 题 )。。实际场景中,函数往往不是简单的 f ( x ) f(x) f ( x ) x ( t ) x(t) x ( t ) T ( x ) T(x) T ( x ) T ( t ) = T ( x ( t ) ) T(t) = T(x(t)) T ( t ) = T ( x ( t )) t t t x x x T T T d T d t \frac{dT}{dt} d t d T T ( t ) T(t) T ( t ) d T d x \frac{dT}{dx} d x d T d x d t \frac{dx}{dt} d t d x
复合函数 (Composite Function)是指一个函数的输出作为另一个函数的输入。设 u = g ( x ) u = g(x) u = g ( x ) y = f ( u ) y = f(u) y = f ( u ) y = f ( g ( x ) ) y = f(g(x)) y = f ( g ( x )) f f f g g g f ∘ g f \circ g f ∘ g y = sin ( x 2 ) y = \sin(x^2) y = sin ( x 2 ) u = x 2 u = x^2 u = x 2 y = sin ( u ) y = \sin(u) y = sin ( u ) y = e x 2 + 1 y = e^{x^2 + 1} y = e x 2 + 1 u = x 2 + 1 u = x^2 + 1 u = x 2 + 1 y = e u y = e^u y = e u
链式法则 (Chain Rule)正是解决复合函数求导问题的有力工具。它告诉我们复合函数的导数等于各层函数导数的乘积,y y y x x x y y y u u u u u u x x x x x x u u u u u u y y y y = f ( u ) y = f(u) y = f ( u ) u = g ( x ) u = g(x) u = g ( x ) y = f ( g ( x ) ) y = f(g(x)) y = f ( g ( x )) x x x d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} d x d y = d u d y ⋅ d x d u ( f ∘ g ) ′ ( x ) = f ′ ( g ( x ) ) ⋅ g ′ ( x ) (f \circ g)'(x) = f'(g(x)) \cdot g'(x) ( f ∘ g ) ′ ( x ) = f ′ ( g ( x )) ⋅ g ′ ( x )
举个具体例子,有 y = sin ( x 2 ) y = \sin(x^2) y = sin ( x 2 ) d y d x \frac{dy}{dx} d x d y u = x 2 u = x^2 u = x 2 y = sin u y = \sin u y = sin u d y d x = d y d u ⋅ d u d x = cos u ⋅ 2 x = 2 x cos ( x 2 ) \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} = \cos u \cdot 2x = 2x \cos(x^2) d x d y = d u d y ⋅ d x d u = cos u ⋅ 2 x = 2 x cos ( x 2 )
将多元函数与复合函数结合起来,可以得出链式法则更一般的形式:设 z = f ( x , y ) z = f(x, y) z = f ( x , y ) x = x ( t ) x = x(t) x = x ( t ) y = y ( t ) y = y(t) y = y ( t ) z z z x x x y y y t t t z = f ( x ( t ) , y ( t ) ) z = f(x(t), y(t)) z = f ( x ( t ) , y ( t )) d z d t = ∂ f ∂ x ⋅ d x d t + ∂ f ∂ y ⋅ d y d t \frac{dz}{dt} = \frac{\partial f}{\partial x} \cdot \frac{dx}{dt} + \frac{\partial f}{\partial y} \cdot \frac{dy}{dt} d t d z = ∂ x ∂ f ⋅ d t d x + ∂ y ∂ f ⋅ d t d y
在机器学习中主要关注的是优化问题,微分肯定是主角,但积分作为微积分中另一个重要概念,在概率论、信息论等领域也有着广泛应用。微分研究的是"局部变化率" —— 在某一点处,函数值变化的快慢。积分则研究"全局累积量" —— 在一个区间上,函数值的总体效果。这两个看似相反的问题,却通过 微积分基本定理 紧密联系在一起。
积分概念源于一个古老而实际的问题:如何计算曲线下的面积。譬如,要计算河流横截面的面积以估算流量,或者计算不规则土地的面积。对于直线围成的图形(三角形、矩形),面积公式人们早已熟知;但对于曲线围成的区域,传统几何方法束手无策。积分的解题思路是分割 - 近似 - 求极限 :将不规则区域分割成许多小块,每块用规则图形(如矩形)近似,然后求和,当分割无限细密时,近似值趋于精确值。这种思想不仅解决了面积问题,还推广到更广泛的"累积"问题:累积路程(从速度求位移)、累积质量(从密度求质量)、累积概率(从概率密度求概率)等等。
积分分为定积分 (Definite Integral)和不定积分 (Indefinite Integral)两大类:
定积分计算函数在特定区间上的累积效果。它给出一个具体数值,而不是一个函数。定积分回答"函数在区间 [ a , b ] [a, b] [ a , b ]
不定积分是导数的逆运算。已知一个函数 f ( x ) f(x) f ( x ) F ( x ) F(x) F ( x ) F ′ ( x ) = f ( x ) F'(x) = f(x) F ′ ( x ) = f ( x ) f ( x ) = 2 x f(x) = 2x f ( x ) = 2 x F ( x ) = x 2 + C F(x) = x^2 + C F ( x ) = x 2 + C C C C ( x 2 + C ) ′ = 2 x (x^2 + C)' = 2x ( x 2 + C ) ′ = 2 x
介绍了背景,现在给出定积分的严格定义:设 f ( x ) f(x) f ( x ) [ a , b ] [a, b] [ a , b ] n n n [ x i − 1 , x i ] [x_{i-1}, x_i] [ x i − 1 , x i ] ξ i \xi_i ξ i ∑ i = 1 n f ( ξ i ) Δ x i \sum_{i=1}^{n} f(\xi_i) \Delta x_i ∑ i = 1 n f ( ξ i ) Δ x i Δ x i → 0 \Delta x_i \to 0 Δ x i → 0 f ( x ) f(x) f ( x ) [ a , b ] [a, b] [ a , b ]
∫ a b f ( x ) d x \int_a^b f(x) \, dx ∫ a b f ( x ) d x 其中 a a a b b b f ( x ) f(x) f ( x ) d x dx d x x x x f ( x ) > 0 f(x) > 0 f ( x ) > 0 f ( x ) < 0 f(x) < 0 f ( x ) < 0
微分和积分通过微积分基本定理 (Fundamental Theorem of Calculus)紧密联系在一起。这个定理是微积分理论两个重要部分的纽带,它证明了微分和积分运算互逆,微分求变化率,积分求累积量;一个是"拆分",一个是"组装",是同一问题的两个侧面。这为后续发展(如微分方程、变分法)奠定了基础。同时,基本定理还大幅简化了定积分的计算,从复杂的极限过程简化为找原函数代入端点。整个微积分基本定理分为两部分:
第一基本定理 (微分与积分的关系)
设 f ( x ) f(x) f ( x ) [ a , b ] [a, b] [ a , b ] F ( x ) = ∫ a x f ( t ) d t F(x) = \int_a^x f(t) \, dt F ( x ) = ∫ a x f ( t ) d t F ( x ) F(x) F ( x ) [ a , b ] [a, b] [ a , b ] F ′ ( x ) = f ( x ) F'(x) = f(x) F ′ ( x ) = f ( x )
这个定理告诉我们:积分的导数等于被积函数。也就是说,积分是微分的逆运算,如果先对 f f f F F F F F F f f f F ( x ) = ∫ a x f ( t ) d t F(x) = \int_a^x f(t) \, dt F ( x ) = ∫ a x f ( t ) d t y = f ( t ) y = f(t) y = f ( t ) a a a x x x x x x Δ x \Delta x Δ x f ( x ) ⋅ Δ x f(x) \cdot \Delta x f ( x ) ⋅ Δ x Δ x \Delta x Δ x f ( x ) f(x) f ( x ) f ( x ) f(x) f ( x )
第二基本定理 (牛顿 - 莱布尼茨公式)
设 f ( x ) f(x) f ( x ) [ a , b ] [a, b] [ a , b ] G ( x ) G(x) G ( x ) f ( x ) f(x) f ( x ) G ′ ( x ) = f ( x ) G'(x) = f(x) G ′ ( x ) = f ( x ) ∫ a b f ( x ) d x = G ( b ) − G ( a ) \int_a^b f(x) \, dx = G(b) - G(a) ∫ a b f ( x ) d x = G ( b ) − G ( a )
这个公式也称为牛顿 - 莱布尼茨公式,是微积分中最著名的公式之一。它告诉我们:要计算定积分,只需要找到被积函数的原函数,然后代入端点求值即可。这大大简化了积分的计算,原本需要用"分割、近似、求极限"的复杂过程,现在只需找到原函数并求差值。
通过一个具体例子来展示牛顿 - 莱布尼茨公式对积分计算的简化,假设要计算 ∫ 0 1 2 x d x \int_0^1 2x \, dx ∫ 0 1 2 x d x
方法一(分割求极限):将区间分成 n n n Δ x = 1 / n \Delta x = 1/n Δ x = 1/ n n → ∞ n \to \infty n → ∞ 1 1 1 ∑ i = 1 n f ( x i ) Δ x = ∑ i = 1 n 2 i n ⋅ 1 n = 2 n 2 ∑ i = 1 n i = 2 n 2 ⋅ n ( n + 1 ) 2 = n + 1 n \sum_{i=1}^{n} f(x_i) \Delta x = \sum_{i=1}^{n} \frac{2i}{n} \cdot \frac{1}{n} = \frac{2}{n^2} \sum_{i=1}^{n} i = \frac{2}{n^2} \cdot \frac{n(n+1)}{2} = \frac{n+1}{n} i = 1 ∑ n f ( x i ) Δ x = i = 1 ∑ n n 2 i ⋅ n 1 = n 2 2 i = 1 ∑ n i = n 2 2 ⋅ 2 n ( n + 1 ) = n n + 1 方法二(牛顿 - 莱布尼茨公式):f ( x ) = 2 x f(x) = 2x f ( x ) = 2 x G ( x ) = x 2 G(x) = x^2 G ( x ) = x 2 ( x 2 ) ′ = 2 x (x^2)' = 2x ( x 2 ) ′ = 2 x ∫ 0 1 2 x d x = G ( 1 ) − G ( 0 ) = 1 2 − 0 2 = 1 \int_0^1 2x \, dx = G(1) - G(0) = 1^2 - 0^2 = 1 ∫ 0 1 2 x d x = G ( 1 ) − G ( 0 ) = 1 2 − 0 2 = 1 当数学从研究"一个变量如何影响结果"转向"多个变量共同作用如何决定结果"时,偏导数提供了一个自然的切入点:固定其他变量,只观察一个变量的影响。这种降维思考的策略,将复杂的多元问题分解为熟悉的单变量问题,体现了科学研究中化繁为简的智慧。偏导数刻画了沿坐标轴方向的变化,梯度则将这些分散的信息整合成一个向量,揭示了函数在各方向变化的"全景图"。梯度指向函数值增长最快的方向,这一几何性质看似简单,却是机器学习中梯度下降算法的灵魂所在。多元函数是另外一个维度的多变量复合嵌套关系,链式法则为我们提供了拆解这种复杂性的工具。总变化率等于各路径贡献之和,这是一种分治的思想,在机器学习中也完全被借鉴过去,神经网络正是深度复合函数的典型代表,反向传播算法本质上就是链式法则的系统性应用。
下一章将通过 NumPy 和 PyTorch 的实践,将这些抽象概念转化为可执行的代码,让数学思想在程序中落地生根。
证明方向向量的定义 D u f ( x 0 , y 0 ) = lim h → 0 f ( x 0 + h u 1 , y 0 + h u 2 ) − f ( x 0 , y 0 ) h D_{\mathbf{u}} f(x_0, y_0) = \lim_{h \to 0} \frac{f(x_0 + h u_1, y_0 + h u_2) - f(x_0, y_0)}{h} D u f ( x 0 , y 0 ) = lim h → 0 h f ( x 0 + h u 1 , y 0 + h u 2 ) − f ( x 0 , y 0 ) D u f = ∇ f ⋅ u D_{\mathbf{u}} f = \nabla f \cdot \mathbf{u} D u f = ∇ f ⋅ u
参考答案 这实际上是一个复合函数的导数问题:令 g ( h ) = f ( x 0 + h u 1 , y 0 + h u 2 ) g(h) = f(x_0 + h u_1, y_0 + h u_2) g ( h ) = f ( x 0 + h u 1 , y 0 + h u 2 ) g ′ ( 0 ) g'(0) g ′ ( 0 ) x ( h ) = x 0 + h u 1 x(h) = x_0 + h u_1 x ( h ) = x 0 + h u 1 y ( h ) = y 0 + h u 2 y(h) = y_0 + h u_2 y ( h ) = y 0 + h u 2 d g d h = ∂ f ∂ x ⋅ d x d h + ∂ f ∂ y ⋅ d y d h \frac{dg}{dh} = \frac{\partial f}{\partial x} \cdot \frac{dx}{dh} + \frac{\partial f}{\partial y} \cdot \frac{dy}{dh} d h d g = ∂ x ∂ f ⋅ d h d x + ∂ y ∂ f ⋅ d h d y 计算路径导数:d x d h = u 1 \frac{dx}{dh} = u_1 d h d x = u 1 d y d h = u 2 \frac{dy}{dh} = u_2 d h d y = u 2
D u f = ∂ f ∂ x ⋅ u 1 + ∂ f ∂ y ⋅ u 2 D_{\mathbf{u}} f = \frac{\partial f}{\partial x} \cdot u_1 + \frac{\partial f}{\partial y} \cdot u_2 D u f = ∂ x ∂ f ⋅ u 1 + ∂ y ∂ f ⋅ u 2 上式右边正好是向量 ( ∂ f ∂ x , ∂ f ∂ y ) (\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}) ( ∂ x ∂ f , ∂ y ∂ f ) ( u 1 , u 2 ) (u_1, u_2) ( u 1 , u 2 ) ∇ f \nabla f ∇ f u \mathbf{u} u
D u f = ∇ f ⋅ u D_{\mathbf{u}} f = \nabla f \cdot \mathbf{u} D u f = ∇ f ⋅ u 设 f ( x , y ) = x 2 y + y 3 f(x, y) = x^2 y + y^3 f ( x , y ) = x 2 y + y 3 ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f ∇ f \nabla f ∇ f
参考答案 求 ∂ f ∂ x \frac{\partial f}{\partial x} ∂ x ∂ f y y y ∂ f ∂ x = 2 x y \frac{\partial f}{\partial x} = 2xy ∂ x ∂ f = 2 x y
求 ∂ f ∂ y \frac{\partial f}{\partial y} ∂ y ∂ f x x x ∂ f ∂ y = x 2 + 3 y 2 \frac{\partial f}{\partial y} = x^2 + 3y^2 ∂ y ∂ f = x 2 + 3 y 2
梯度:∇ f = ( 2 x y , x 2 + 3 y 2 ) \nabla f = (2xy, x^2 + 3y^2) ∇ f = ( 2 x y , x 2 + 3 y 2 )
在点 ( 1 , 2 ) (1, 2) ( 1 , 2 ) ∇ f ( 1 , 2 ) = ( 4 , 13 ) \nabla f(1, 2) = (4, 13) ∇ f ( 1 , 2 ) = ( 4 , 13 )
设 z = x 2 + y 2 z = x^2 + y^2 z = x 2 + y 2 x = t + 1 x = t + 1 x = t + 1 y = t 2 y = t^2 y = t 2 d z d t \frac{dz}{dt} d t d z
参考答案 方法一(链式法则):
d z d t = ∂ z ∂ x ⋅ d x d t + ∂ z ∂ y ⋅ d y d t \frac{dz}{dt} = \frac{\partial z}{\partial x} \cdot \frac{dx}{dt} + \frac{\partial z}{\partial y} \cdot \frac{dy}{dt} d t d z = ∂ x ∂ z ⋅ d t d x + ∂ y ∂ z ⋅ d t d y 计算:
∂ z ∂ x = 2 x \frac{\partial z}{\partial x} = 2x ∂ x ∂ z = 2 x ∂ z ∂ y = 2 y \frac{\partial z}{\partial y} = 2y ∂ y ∂ z = 2 y d x d t = 1 \frac{dx}{dt} = 1 d t d x = 1 d y d t = 2 t \frac{dy}{dt} = 2t d t d y = 2 t 因此:d z d t = 2 x ⋅ 1 + 2 y ⋅ 2 t = 2 ( t + 1 ) + 2 t 2 ⋅ 2 t = 2 t + 2 + 4 t 3 \frac{dz}{dt} = 2x \cdot 1 + 2y \cdot 2t = 2(t+1) + 2t^2 \cdot 2t = 2t + 2 + 4t^3 d t d z = 2 x ⋅ 1 + 2 y ⋅ 2 t = 2 ( t + 1 ) + 2 t 2 ⋅ 2 t = 2 t + 2 + 4 t 3
方法二(直接代入验证):z = ( t + 1 ) 2 + t 4 = t 2 + 2 t + 1 + t 4 z = (t+1)^2 + t^4 = t^2 + 2t + 1 + t^4 z = ( t + 1 ) 2 + t 4 = t 2 + 2 t + 1 + t 4 d z d t = 2 t + 2 + 4 t 3 \frac{dz}{dt} = 2t + 2 + 4t^3 d t d z = 2 t + 2 + 4 t 3
两种方法结果一致。
设 f ( x , y ) = x 2 − y 2 f(x, y) = x^2 - y^2 f ( x , y ) = x 2 − y 2 f f f ( 1 , 1 ) (1, 1) ( 1 , 1 ) u = ( 1 2 , 1 2 ) \mathbf{u} = (\frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}}) u = ( 2 1 , 2 1 )
参考答案 首先计算梯度:∇ f = ( 2 x , − 2 y ) \nabla f = (2x, -2y) ∇ f = ( 2 x , − 2 y )
在点 ( 1 , 1 ) (1, 1) ( 1 , 1 ) ∇ f ( 1 , 1 ) = ( 2 , − 2 ) \nabla f(1, 1) = (2, -2) ∇ f ( 1 , 1 ) = ( 2 , − 2 )
方向导数:D u f = ∇ f ⋅ u = ( 2 , − 2 ) ⋅ ( 1 2 , 1 2 ) = 2 2 − 2 2 = 0 D_{\mathbf{u}} f = \nabla f \cdot \mathbf{u} = (2, -2) \cdot (\frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}}) = \frac{2}{\sqrt{2}} - \frac{2}{\sqrt{2}} = 0 D u f = ∇ f ⋅ u = ( 2 , − 2 ) ⋅ ( 2 1 , 2 1 ) = 2 2 − 2 2 = 0
解释:方向 u \mathbf{u} u
判断函数 f ( x , y ) = x 2 + 2 y 2 + 2 x y f(x, y) = x^2 + 2y^2 + 2xy f ( x , y ) = x 2 + 2 y 2 + 2 x y
参考答案 计算一阶偏导数:
∂ f ∂ x = 2 x + 2 y \frac{\partial f}{\partial x} = 2x + 2y ∂ x ∂ f = 2 x + 2 y ∂ f ∂ y = 4 y + 2 x \frac{\partial f}{\partial y} = 4y + 2x ∂ y ∂ f = 4 y + 2 x 计算二阶偏导数:
∂ 2 f ∂ x 2 = 2 \frac{\partial^2 f}{\partial x^2} = 2 ∂ x 2 ∂ 2 f = 2 ∂ 2 f ∂ y 2 = 4 \frac{\partial^2 f}{\partial y^2} = 4 ∂ y 2 ∂ 2 f = 4 ∂ 2 f ∂ x ∂ y = 2 \frac{\partial^2 f}{\partial x \partial y} = 2 ∂ x ∂ y ∂ 2 f = 2 ∂ 2 f ∂ y ∂ x = 2 \frac{\partial^2 f}{\partial y \partial x} = 2 ∂ y ∂ x ∂ 2 f = 2 海森矩阵:H = [ 2 2 2 4 ] \mathbf{H} = \begin{bmatrix} 2 & 2 \\ 2 & 4 \end{bmatrix} H = [ 2 2 2 4 ]
计算特征值:det ( H − λ I ) = ∣ 2 − λ 2 2 4 − λ ∣ = ( 2 − λ ) ( 4 − λ ) − 4 = λ 2 − 6 λ + 4 = 0 \det(\mathbf{H} - \lambda \mathbf{I}) = \begin{vmatrix} 2-\lambda & 2 \\ 2 & 4-\lambda \end{vmatrix} = (2-\lambda)(4-\lambda) - 4 = \lambda^2 - 6\lambda + 4 = 0 det ( H − λ I ) = 2 − λ 2 2 4 − λ = ( 2 − λ ) ( 4 − λ ) − 4 = λ 2 − 6 λ + 4 = 0
解得:λ = 3 ± 5 \lambda = 3 \pm \sqrt{5} λ = 3 ± 5
结论:海森矩阵正定,函数严格凸。
设 f ( x ) = e − x 2 f(x) = e^{-x^2} f ( x ) = e − x 2 ∫ − ∞ ∞ f ( x ) d x \int_{-\infty}^{\infty} f(x) \, dx ∫ − ∞ ∞ f ( x ) d x
参考答案 这个积分是著名的高斯积分:∫ − ∞ ∞ e − x 2 d x = π \int_{-\infty}^{\infty} e^{-x^2} \, dx = \sqrt{\pi} ∫ − ∞ ∞ e − x 2 d x = π
概率论意义:ϕ ( x ) = 1 2 π e − x 2 / 2 \phi(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2} ϕ ( x ) = 2 π 1 e − x 2 /2
由于 ∫ − ∞ ∞ ϕ ( x ) d x = 1 \int_{-\infty}^{\infty} \phi(x) \, dx = 1 ∫ − ∞ ∞ ϕ ( x ) d x = 1
高斯积分在机器学习中广泛出现,譬如:
高斯核函数(RBF 核) 变分推断中的 KL 散度计算 高斯分布的参数估计 证明:若 ∇ f ( x ∗ ) = 0 \nabla f(\mathbf{x}^*) = \mathbf{0} ∇ f ( x ∗ ) = 0 H \mathbf{H} H x ∗ \mathbf{x}^* x ∗ x ∗ \mathbf{x}^* x ∗ f f f
参考答案 这是二阶充分条件的关键结论。
证明思路:
∇ f ( x ∗ ) = 0 \nabla f(\mathbf{x}^*) = \mathbf{0} ∇ f ( x ∗ ) = 0 x ∗ \mathbf{x}^* x ∗ 海森矩阵正定意味着在 x ∗ \mathbf{x}^* x ∗ f ( x ∗ + h ) ≈ f ( x ∗ ) + 1 2 h T H h f(\mathbf{x}^* + \mathbf{h}) \approx f(\mathbf{x}^*) + \frac{1}{2}\mathbf{h}^T \mathbf{H} \mathbf{h} f ( x ∗ + h ) ≈ f ( x ∗ ) + 2 1 h T Hh 由于 H \mathbf{H} H h \mathbf{h} h h T H h > 0 \mathbf{h}^T \mathbf{H} \mathbf{h} > 0 h T Hh > 0 因此 f ( x ∗ + h ) > f ( x ∗ ) f(\mathbf{x}^* + \mathbf{h}) > f(\mathbf{x}^*) f ( x ∗ + h ) > f ( x ∗ ) h \mathbf{h} h 这说明 x ∗ \mathbf{x}^* x ∗ 这个结论在优化算法中有重要应用:当我们找到梯度为零的点后,检查海森矩阵的正定性可以判断这是最小值点还是最大值点或鞍点。