神经网络基础原理
神经网络(Neural Network)这个概念的诞生,源于人类对自身智能本质的追问。大脑是如何思考的?记忆是如何存储的?学习是如何发生的?这些问题的答案最终指向同一个方向:神经元(Neuron)。19 世纪末,神经解剖学通过精细的显微镜观察,首次揭示了神经系统的微观结构,大脑由数以亿计的微小单元组成,这些单元彼此连接,形成复杂的网络。这一发现奠定了现代神经科学的基础,也成为人工神经网络思想的源头。
人工神经网络的发展历程是一部跨越八十年的探索史诗。从 1940 年代的数学模型建立,到 1950 年代的硬件实现,再到 1960 年代的算法突破,每一个阶段都推动着机器智能这一梦想向前迈进。本章将从生物神经元的结构出发,介绍 McCulloch-Pitts 模型、Hebb 学习规则,以及早期感知机的诞生,理解神经网络思想的起源与演进。
智慧的疆界
对人工智能发展历史感兴趣的读者,可以参考阅读笔者的人工智能科普作品《智慧的疆界》
生物神经元结构与启发
大脑是自然界最复杂的器官,成年人类大脑约有 860 亿个神经元,每个神经元又与其他数千个神经元相连,形成一个包含约 100 万亿个连接的庞大网络。这个网络负责感知、思考、记忆、决策,是人类智能的物理载体。一个典型的神经元由三个主要部分组成:细胞体(Cell Body)、树突(Dendrite)和轴突(Axon),如下图所示:
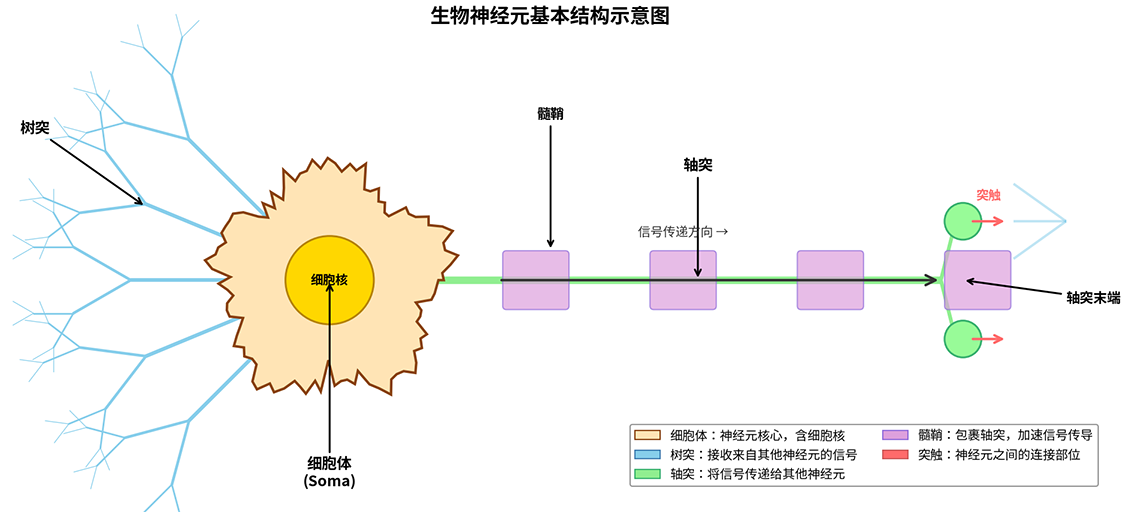
图:生物神经元的基本结构
其中,细胞体是神经元的核心,负责维持生命活动和信息整合;树突是从细胞体延伸出的短而分支的突起,形如树枝,是神经元的"接收器",接收来自其他神经元的信号输入;轴突是从细胞体延伸出的长突起,通常只有一个,是神经元的"发射器",将整合后的信号传递给其他神经元或肌肉细胞;突触末端是与下游神经元树突或细胞体连接的部位,是信号传递的"接口"。
神经信号传递是一个精妙的电化学过程。当神经元接收到足够强的输入信号时,细胞体内会产生一个短暂的电脉冲。这个脉冲沿着轴突传导到末端,触发突触释放神经递质(Neurotransmitter)。神经递质穿过突触间隙,与下游神经元的受体结合,引发其电信号变化。这种信号传递机制有两个关键特点:
- 阈值特性(Threshold Property):神经元只有在输入信号达到一定强度(阈值)时才会产生动作电位。输入信号不足时,神经元保持静默。这与数字电路中的开关行为如出一辙,只有电压超过阈值才导通。
- 全或无特性(All-or-None Property):一旦动作电位产生,其幅度和形状基本固定,不随输入强度变化。更强的输入只会增加动作电位的频率,而非幅度。这一特性使得神经信号可以被视为离散的脉冲而非连续的波形。
生物神经元的工作机制启发了早期研究者思考:能否用数学模型模拟这种结构,从而实现机器智能?关键启发有三点:
- 单元化结构:大脑不是一块均匀的物质,而是由大量相似的微小单元组成的网络。这意味着智能可以通过组合简单单元来实现,无需构建单一的复杂系统。
- 信号整合:每个神经元接收多个输入,整合后决定是否输出。这暗示着一种加权求和的运算,不同输入可能有不同的重要性(权重),神经元综合所有输入后做出决策。
- 阈值决策:神经元只有当整合信号超过阈值时才输出。这是一种二值决策机制,可以用于逻辑运算和分类任务。
正是这些启发,催生了世界上第一个神经元数学模型 —— McCulloch-Pitts 模型。
McCulloch-Pitts 模型
1943 年,美国心理学家沃伦·麦卡洛克(Warren McCulloch)和数学家沃尔特·皮茨(Walter Pitts)在论文《A Logical Calculus of Ideas Immanent in Nervous Activity》中提出了第一个神经元的数学模型,后世称为 McCulloch-Pitts 模型(简称 M-P 模型)。这篇论文不仅开创了人工神经网络的研究领域,还首次揭示了神经网络能够执行逻辑运算,具有计算能力。
M-P 模型将生物神经元抽象为一个二值逻辑单元。设神经元接收 个输入 ,每个输入取值为 0 或 1(对应"无信号"或"有信号")。神经元对这些输入进行加权求和,再与阈值 比较,输出结果 :
其中 是第 个输入的权重,取值为整数,正权重表示兴奋性输入,负权重表示抑制性输入, 是阈值。这一模型恰好对应了生物神经元的三个核心特性:
- 加权求和: 对应神经元对多个输入信号的整合。
- 阈值比较: 对应神经元的阈值特性。
- 二值输出: 对应神经元的"全或无"特性。
麦卡洛克和皮茨的工作揭示了一个关键结论:适当设置权重和阈值,M-P 模型可以实现所有基本逻辑运算。这意味着神经网络本质上是一种逻辑计算系统,通过生物神经元的连接可以像计算机的逻辑门电路一样,完成下面这些操作:
- 逻辑与(AND):设输入 ,权重 ,阈值 。只有当两个输入都为 1 时,加权和 ,输出 ;其他情况输出为 0。这正是 AND 运算的定义。
- 逻辑或(OR):权重 ,阈值 。只要有一个输入为 1,加权和就达到 1,输出为 1。
- 逻辑非(NOT):只有一个输入 ,权重 ,阈值 。当 时,加权和 ,输出 0;当 时,加权和 ,输出 1。这正是 NOT 运算。
更进一步,麦卡洛克和皮茨证明了由多个 M-P 神经元组成的网络可以实现任何有限逻辑表达式,包括存储记忆、识别模式等复杂功能。这一结论具有深远影响,它暗示了大脑本质上可能是一台庞大的逻辑计算机,而构建"人工大脑"的第一步就是构建能够执行逻辑运算的神经元网络。后世因此将 M-P 模型称为人工神经网络研究的起点,其意义在于:
- 首次将神经活动形式化:在此之前,神经科学主要依靠实验观察,缺乏数学描述。M-P 模型将神经元抽象为数学对象,开启了"计算神经科学"的新领域。
- 揭示了神经网络的计算本质:证明神经网络能执行逻辑运算,暗示智能可能与计算密切相关。这一思想影响了后来的认知科学和人工智能研究。
- 为计算机科学奠基:M-P 模型发表的同一年,图灵提出了图灵机概念。两者都强调了"计算"作为智能基础的重要性,共同奠定了现代计算机科学的理论基础。值得一提的是,提出现代计算机冯·诺依曼体系结构的《First Draft of a Report on the EDVAC》,全文只有一篇外部引用正是麦卡洛克和皮茨的神经网络论文。现代计算机中寄存器(Cache)、内部存储器(RAM)的记忆原理(电信号循环刷新产生记忆),便直接源于他们两位的工作。
然而,M-P 模型也有明显的局限,网络权重和阈值需要人工设定,模型本身并没有学习能力。如何让网络自动调整参数,从数据中学习规律,几年后,心理学家唐纳德·赫布(Donald Hebb)针对这一问题提出了一种解决方案。
Hebb 学习规则
1949 年,加拿大心理学家唐纳德·赫布(Donald Hebb)在著作《The Organization of Behavior》中提出了一个关于学习和记忆的神经科学理论。其中最著名的内容被称为 Hebb 学习规则(Hebb's Rule),它解释了神经元之间的连接强度如何在学习过程中发生变化。
Hebb 规则的核心思想可以用一句话概括:
"当两个神经元同时激活时,它们之间的连接会增强。"
更正式的表述是:如果神经元 A 的轴突反复或持续参与激发神经元 B,那么 A 与 B 之间的突触传递效率会增加。这一原则后来被简化为著名的口号"一起激发,一起连线"(Cells that fire together, wire together)。用数学语言描述,设神经元 到神经元 的连接权重为 ,则权重的更新规则为:
其中 是神经元 的输出(作为输入传递给神经元 ), 是神经元 的输出, 是学习率(控制更新幅度)。这一规则在神经网络中被总结为相关性学习:如果两个神经元经常同时激活,说明它们在处理相同的信息,因此连接权重应该加强,以便未来更好地协同工作。反之,如果一个激活而另一个不激活,连接权重则不应被加强。
Hebb 规则最初是一个理论假设,但后来得到了大量神经科学实验的支持。突触可塑性(Synaptic Plasticity)是神经科学的核心概念之一,指的是突触连接强度可以根据神经活动而改变。其中最著名的现象是长时程增强(Long-Term Potentiation, LTP)。1973 年,挪威神经科学家泰耶·洛莫在海马体实验中首次观察到 LTP 现象,实验发现当两个神经元以特定频率同时激活时,它们之间的突触连接会显著增强,且这种增强可以持续数小时甚至数天。这正是 Hebb 规则预测的现象 —— 反复的共同激活导致连接强化。
LTP 被认为是学习和记忆的神经机制基础。学习新知识时,相关神经元反复共同激活,突触连接增强;回忆时,增强的连接使相关信息更易提取。这一机制解释了"熟能生巧"的神经本质,反复练习强化了相关神经通路。
Hebb 规则为人工神经网络引入了"学习"的概念。在此之前,M-P 模型的权重需要人工设定,Hebb 规则暗示了一种自动调整权重的方法,根据神经元的活动相关性更新权重,这启发了后续多种学习算法的发展:
- 无监督学习:Hebb 规则不需要外部标签指导,只需根据神经元自身的活动调整连接。这是无监督学习思想的源头。
- 联想记忆:Hebb 规则天然适合构建联想记忆网络。当两个概念(如"苹果"和"红色")反复同时出现时,网络中对应的神经元连接增强,形成联想。之后看到苹果,自然会联想到红色。
- 竞争学习:Hebb 规则的延伸,引入竞争机制,最强的神经元获得权重更新,弱者被抑制。这发展出了自组织映射(SOM)等方法。
然而,原始的 Hebb 规则也有局限,它只考虑共同激活,忽略了不共同激活的情况。如果一个神经元激活而另一个不激活,它们之间的连接是否应该减弱?这一问题在后续研究中得到了完善,形成了更完整的突触可塑性模型。
神经网络的早期发展历史
从 M-P 模型到 Hebb 规则,神经网络思想的萌芽期已经奠定了理论基础。接下来的二十年,研究者们将这些思想付诸实践,构建出第一个可运行的神经网络系统。
1940 年代:理论奠基
1943 年 M-P 模型的发表是神经网络研究的起点。这篇论文的意义在于首次将神经活动抽象为数学运算,并证明了神经网络的逻辑计算能力。同年,图灵发表《On Computable Numbers》,提出了图灵机概念。两者共同开启了"计算与智能"的理论探索。
1949 年 Hebb 规则的提出,为神经网络引入了学习机制。虽然 Hebb 主要关注生物神经系统的学习原理,但其思想直接启发了人工神经网络的学习算法设计。
1950 年代:硬件实现
1951 年,马文·明斯基(Marvin Minsky)和迪恩·埃德蒙兹(Dean Edmonds)在哈佛大学建造了第一台神经网络计算机 SNARC(Stochastic Neural Analog Reinforcement Calculator)。这台机器使用 3000 个真空管和 40 个"神经元"模拟自动学习过程,虽然功能有限,但证明了神经网络可以在硬件上实现。
1957 年,心理学家弗兰克·罗森布拉特(Frank Rosenblatt)在康奈尔大学航空实验室提出了感知机(Perceptron)模型。感知机是 M-P 模型的延伸,引入了学习算法,能够自动调整权重。1958 年,罗森布拉特建造了 Mark I 感知机硬件,使用 400 个光电传感器作为输入,能够识别简单的几何形状。这是第一个能够从数据中学习的神经网络系统。
感知机的诞生标志着神经网络从理论研究进入实践应用阶段。它不仅能执行逻辑运算,还能学习分类任务,引发了第一次神经网络研究热潮。《纽约时报》称其为"电子大脑",预言它终将"行走、说话、看见、书写、自我复制并意识到自身存在",这种近乎科幻的期待,反映了当时公众对人工智能的乐观想象。
1960 年代:高潮与低谷
1960 年,斯坦福大学的伯纳德·威德罗(Bernard Widrow)和泰德·霍夫(Ted Hoff)提出了自适应线性单元(ADALINE)模型。ADALINE 使用连续的线性输出而非二值输出,并引入了最小均方误差(LMS)学习算法(后称 Widrow-Hoff 学习规则)。这是梯度下降学习算法的早期形式,后来成为神经网络训练的核心方法。
1962 年,罗森布拉特出版了《Principles of Neurodynamics》一书,系统阐述了感知机理论,包括感知机学习算法和收敛定理。书中证明:如果两类数据线性可分,感知机学习算法必能在有限步内收敛到正确解。这是神经网络领域第一个严格的学习理论证明。
转折出现在 1969 年。明斯基和西摩·派普特(Seymour Papert)出版《Perceptrons》一书,对感知机的能力提出了尖锐批评。书中证明感知机无法解决异或问题(XOR Problem),因为 XOR 是非线性可分的。一个简单的两层神经网络就能解决 XOR 问题,但当时的理论无法有效训练多层网络。这本书的影响巨大,导致神经网络研究陷入长达十年的低谷。
回顾这段历史,神经网络的发展并非坦途,而是螺旋上升的过程,每一次突破都暴露出新的局限,每一次低谷又孕育着转机。1969 年的"感知机危机"虽然暂时抑制了研究热情,但也指明了未来方向:突破单层网络,探索多层网络的学习方法。这一方向在 1980 年代反向传播算法出现后终于实现。
本章小结
本章追溯了神经网络思想的起源,从生物神经元的结构出发,介绍了 McCulloch-Pitts 模型、Hebb 学习规则,以及早期感知机的诞生。这段历史展现了从自然到人工的探索路径:观察大脑结构,抽象为数学模型,最终实现为计算系统。M-P 模型的核心贡献在于将神经元抽象为二值逻辑单元,证明了神经网络具备执行逻辑运算的能力。Hebb 规则引入了相关性学习的思想,证明了权重可根据神经活动自动调整,这一洞见至今仍是深度学习的基础。感知机将这些思想整合,构建了第一个可学习的神经网络系统,并建立了学习理论。
然而,早期神经网络也暴露了局限性,单层网络无法解决非线性问题(如 XOR),多层网络的训练方法尚未发现。这些局限暂时抑制了研究热情,但也指明了未来的方向。下一章将深入感知机模型,探究其结构、学习算法、几何解释,以及那个著名的 XOR 问题。
练习题
解释 McCulloch-Pitts 模型如何实现逻辑运算。设计一个 M-P 神经元实现"三输入 AND 门"(三个输入都为 1 时输出 1),写出权重和阈值的设置。
参考答案
三输入 AND 门要求:只有当 同时满足时,输出 ;否则输出 。
设计方案:
- 输入:
- 权重:(等权)
- 阈值:
验证:
- 当 时,加权和 ,输出
- 当任意输入为 0 时,加权和 ,输出
这正是 AND 运算的定义。阈值 的设置确保只有"三个输入全为 1"这一种情况能满足阈值条件。
Hebb 学习规则的核心思想是"一起激发,一起连线"。请从神经科学和机器学习两个角度解释这一规则的含义和局限性。
参考答案
神经科学角度:
Hebb 规则描述了突触可塑性的一种形式。当突触前神经元(A)反复激活突触后神经元(B)时,A 到 B 的突触连接会增强。这对应神经科学中观察到的"长时程增强"(LTP)现象。Hebb 规则解释了学习和记忆的神经机制:反复的共同活动强化相关神经通路,形成记忆痕迹。
局限性:
- Hebb 规则只考虑共同激活的情况,忽略了一个激活而另一个不激活的情景。实际上,突触还存在长时程抑制(LTD),当突触前神经元激活而突触后神经元不激活时,连接可能减弱。
- Hebb 规则没有时间窗口的概念。实际上,突触可塑性对活动的时间顺序敏感:如果 A 激活后几毫秒内 B 激活(正向顺序),连接增强;如果 B 激活后 A 激活(反向顺序),连接可能减弱。这被称为时间依赖可塑性(STDP)。
机器学习角度:
Hebb 规则是最早的无监督学习算法。权重更新公式 意味着:当输入 和输出 同时为高值时,权重增加。这捕捉了相关性学习,既网络学习输入与输出之间的统计相关性。
局限性:
- Hebb 规则会导致权重无限增长。没有机制限制或衰减权重,长期学习后权重可能过大,导致网络不稳定。实际应用中需要加入权重衰减或归一化机制。
- Hebb 规则没有目标信号,无法进行有监督学习。对于分类任务,需要外部标签指导学习方向。感知机算法正是引入了错误信号,将 Hebb 规则扩展为有监督学习。
解释为什么感知机无法解决 XOR 问题。从几何角度和数学角度分析,并说明多层感知机如何解决这一问题。
参考答案
几何角度:
XOR 问题的数据分布如下:
- :点在原点,标签 0
- :点在 y 轴,标签 1
- :点在 x 轴,标签 1
- :点在(1,1),标签 0
在二维平面上,这四个点形成"对角线分布":标签为 1 的两个点位于一条对角线上,标签为 0 的两个点位于另一条对角线上。
感知机的决策边界是一条直线。要在平面上用一条直线将两类分开,必须存在一条直线能完全分离两类点。但观察数据分布,不存在这样的直线:任何直线要么将两个标签 1 的点分开,要么将标签 0 和标签 1 的点混在一起。这就是"非线性可分"的几何含义。
数学角度:
感知机的输出方程为 ,决策边界是直线 。
假设存在权重 能正确分类 XOR 数据:
- 对于 输出 0,要求
- 对于 输出 1,要求 ,即
- 对于 输出 1,要求 ,即
- 对于 输出 0,要求
由前三个条件得 ,但第四个条件要求 ,矛盾。因此不存在满足所有条件的权重,证明感知机无法解决 XOR 问题。
多层感知机如何解决:
单层感知机的决策边界是直线,但多层感知机可以通过组合多个线性边界形成非线性边界。一个两层感知机可以解决 XOR:
第一层两个神经元分别实现:
- 神经元 1:(检测"至少一个为 1")
- 神经元 2:(检测"两个都为 1")
第二层神经元实现:
- 输出:(实现"至少一个为 1"但"不是两个都为 1")
验证:
- :, 输出 ✓
- :, 输出 ✓
- :, 输出 ✓
- :, 输出 ✓
这证明了多层网络的表达能力超过单层网络,能够解决非线性问题。关键洞察:多层网络通过组合线性边界构建非线性边界,一层提取特征,另一层组合决策。